


在虚拟现实、增强现实、游戏和人机互动等领域,经常需要让虚拟人物和屏幕外的玩家互动。 这种互动是实时的,要求虚拟人物根据操作者的动作进行动态调整。 有些互动还涉及物体,像是和和虚拟人物一起搬动一把椅子,这就需要特别关注操作者手部的精确动作。 智慧、可互动的虚拟人物的出现,将极大地提升人类玩家与虚拟人物的社交体验,带来全新的娱乐方式。

在该研究中,作者专注于人与虚拟人物的互动任务,特别是涉及物体的互动,提出了一项名为线上全身动作反应合成的新方案。 该方案将基于人类的动作产生虚拟人物的反应。 以往的研究主要关注人与人的互动,不考虑任务中的物体,产生的身体反应也没有手部动作。 此外,以往工作也没有将任务视为线上的推理,在实际情况中虚拟人物根据实施情况对下一步进行预判。
为了支持新任务,作者首先构建了两个数据集,分别命名为 HHI 和 CoChair,并提出了一个统一的方法。 具体来说,作者首先构建了社交可供性(Affordance)表示。 为了做到这一点,他们选择了一个社交可供性载体,再使用SE(3)等变神经网络为该载体学习局部坐标系,最后将其社交可供性规范化。 此外,作者还提出了一种社交可供性预测的方案,使虚拟人物能够基于预测进行决策。
实验证明,该研究中的方法可以在 HHI 和 CoChair 数据集上有效产生高质量的反应动作,并且能在一块 A100 上实现 25 FPS 的实时推理速度。 此外,作者还在现有的人类互动数据集Interhuman和Chi3D上验证了方法的有效性。


数据集构建
本文中,作者构建了两个数据集来支持线上全身动作反应合成任务,一个是双人互动的数据集 HHI,另一个是双人与物体互动的数据集 CoChair。

HHI 数据集是一个大规模的全身动作反应数据集,包含30个互动类别、10 对人体骨骼类型和总共5000个互动序列。
HHI 数据集有三个特点。 第一个特点是包含多人全身互动,包括身体和手部互动。 作者认为在多人互动中,手部的互动无法忽视,在握手、拥抱和交接过程中,都通过手部来传递丰富的信息。 第二个特点是 HHI 数据集可以区分明确的行为发起者和反应者。 例如,在握手、指向方向、问候、交接等情况下,HHI 数据集可以确定动作的发起者,这有助于研究者更好地定义和评估这个问题。 第三个特点是 HHI 数据集包含的互动和反应的类型更丰富多样,不仅包括两个人之间 30 种类型互动,还提供了针对同一行动者的多个合理反应。 例如,当有人向你打招呼时,你可以点头回应,用一只手回应,或者双手回应。 这也是一种自然的特征,但以前的数据集很少关注到这一点并进行讨论。
CoChair是一个大规模的多人和物体互动数据集,其中包括8个不同的椅子,5种互动模式和10对不同的骨架,总共3000个序列。 CoChair 有两个重要的特点:其一,CoChair 在协作过程中存在信息不对称。 每一个行动都有一个(知道携带物的目的地的)执行者/发起者和一个(不知道目的地的)反应者。 其二,它具有多样的携带模式。 资料集包括五种携带模式:单手固定携带、单手移动携带、双手固定携带、双手移动携带和双手灵活携带。

方法
社交可供性载体指编码社交可供性信息的对象或人。 当人类与虚拟人物互动时,人类通常直接或间接地与虚拟人物接触。 而当涉及物体时,人类通常会接触物体。
为了模拟互动中的直接或潜在接触信息,需要选择一个载体来同时表征人类、载体本身以及它们之间的关系。 在该研究中,载体指人类可能接触的物体或虚拟人物模板。
基于此,作者定义了以载体为中心的社交可供性表示。 具体而言,给定一个载体,研究者对人类行为进行编码,以获得密集的人 – 载体联合表示。 基于这一表示,作者提出了一种社交可供性表示,其中包含人类行为的动作、载体的动态几何特征以及每个时间步骤中的人 – 载体关系。
需要注意的是,社交可供性表示指的是从开始时刻到特定时间步骤的数据流程,而不是单帧的表示。 这种方法的优势在于将载体的局部区域与人类的行为运动密切关联,形成了便于网络学习的表示。

通过社交可供性表示,作者进一步采用社交可供性规范化来简化表达空间。 第一步是学习载体的局部框架。 通过SE(3)等变网络,学习得到载体的局部坐标系。 具体来说,首先将人类的动作转化为每个局部坐标系的动作。 接下来,作者从每个点的视角对人类角色的动作进行密集编码,以获得一个密集的以载体为中心的动作表示。 这可以被视为将一个「观察者」 绑定到载体上的每个局部点上,每个「观察者」 都从第一人称视角对人类的动作进行编码。 这种方法的优势在于在对人类,虚拟人物以及物体之间的接触产生的信息进行建模的同时,社交可供性规范化简化了社交可供性的分布,并促进了网络学习。
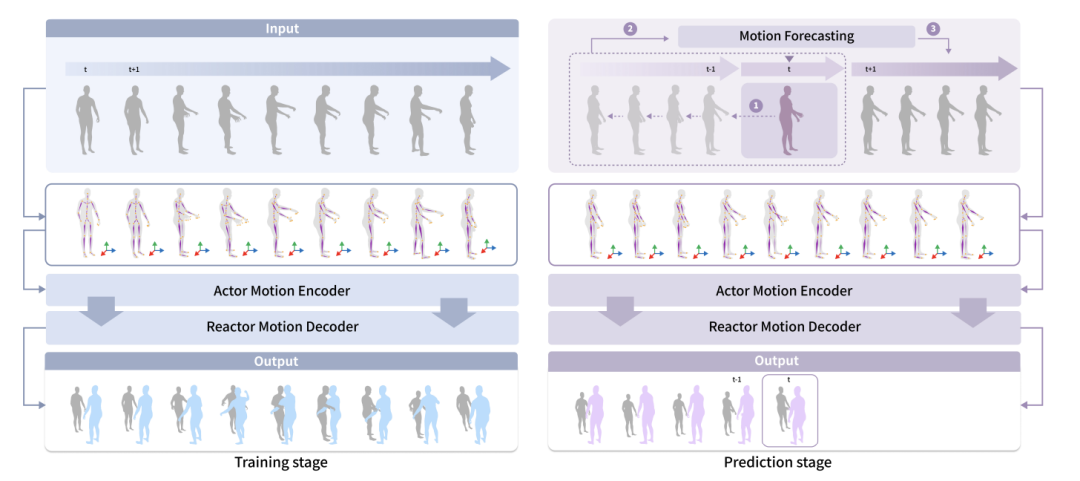
为了预测和虚拟人物互动的人类的行为,作者提出了社交可供性预测模块。 在真实情况下,虚拟人物只能观察到人类行为的历史动态。 而作者认为虚拟物人应该具备预测人类行为的能力,以便更好地规划自己的动作。 例如,当有人抬手并向你走过来时,你可能会认为他们要与你握手,并做好迎接握手的准备。
在训练阶段,虚拟人物可以观察到人类的所有动作。 在真实世界的预测阶段,虚拟人物只能观察到人类行为的过去动态。 而提出的预测模块可以预测人类将要采取的动作,以提高虚拟人物的感知能力。 作者使用一个运动预测模块来预测人类行为者的动作和物体的动作。 双人互动中,作者使用了 HumanMAC 作为预测模块。 在双人与物体互动中,作者基于InterDiff构建了运动预测模块,并添加了一个先验条件,即人-物接触是稳定的,以简化对物体运动的预测难度。
实验
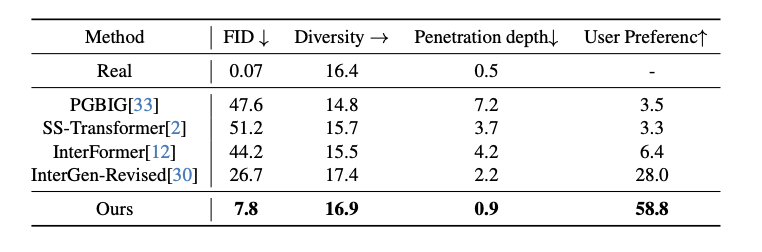
定量测试可以看出该研究的方法在所有度量指标上都优于现有方法。 为了验证方法中每个设计的有效性,作者在 HHI 数据集上进行了消融实验。 可以看出,没有社交可供性规范化时,该方法的表现显著下降。 这表明使用社交可供性规范化来简化特征空间复杂性是必要的。 没有社交可供性预测,文中的方法失去了预测人类行为者动作的能力,导致了性能下降。 为了验证使用局部坐标系的必要性,作者还比较了使用全局坐标系的效果,可以看出局部坐标系显著更好。 这也表明使用局部坐标系描述局部几何和潜在接触是有价值的。

从可视化结果可以看到,与以往相比,使用文中方法训练过的虚拟人物的反应更快,并且能够更好地捕捉到局部的手势,在协作中产生更逼真和自然的抓取动作。
更多研究细节,可参考原论文。