Meta利用之前所发布的可商用大型语言模型Llama 2做为基础,推出程序开发用的语言模型Code Llama。 Code Llama总共有三种变体,第一种是基础代码模型,第二种是针对Python微调的模型,第三种则是针对自然语言指令进行微调的模型变体。 与Llama 2相同,Code Llama也是可免费用于研究和商业用途。
Code Llama使用更多代码数据集训练,并且从该数据集撷取更多数据,进行长时间的训练而成,是专门处理代码的Llama 2模型。 因此Code Llama具有更强的代码编写能力,可以根据程序以及自然语言提示,生成代码或是有关代码的自然语言响应,执行代码完成和调试任务,支持的程式语言包括Python、C++、Java、PHP、Typescript、C#和Bash。
根据不同服务和延迟需求,Meta推出三种大小的Code Llama模型,分别具有70亿、130亿和340亿参数,70亿参数的版本可以在单个GPU上运作,最大的340亿模型则能够回传最佳结果,因此用户可以依据需求选用不同大小的模型,针对需要诸如即时代码完成这类低延迟任务,选用70亿、130亿参数的模型更为适合。
这三种大小的模型,皆经过5,000亿代码和相关内容的Token训练,官方提到,70亿、130亿基础模型和指令模型具有FIM(Fill-In-The-Middle)能力,因此能够生成可插入至现有代码中的代码。
FIM使模型能够在现有的文字和代码中插入和填充内容,类似程序开发环境中代码自动完成,或是代码建议功能。 而70亿、130亿基础模型和指令模型具有FIM功能,也就是说用户不需要额外训练或是调整,就可以直接使用该功能。
Code Llama具有处理长序列内容的能力,能够稳定生成10万Token的内容,并且也能够处理高达10万Token的输入。 处理长输入序列的Code Llama能够支持更多的使用情境,像是使用者可以提供更多来自代码库的上下文,并且对更大的代码库进行调试。
由于Python是经过许多代码生成基准测试的语言,而且Python也在人工智能社群扮演重要角色,因此Meta针对Python,额外以1,000亿Python代码Token进行微调,生成Python程序开发专用的Code Llama – Python模型。 另外,Code Llama – Instruct则是针对指令进行微调的模型版本,能够处理自然语言指令输入和输出,更好地理解用户所给出的指令。
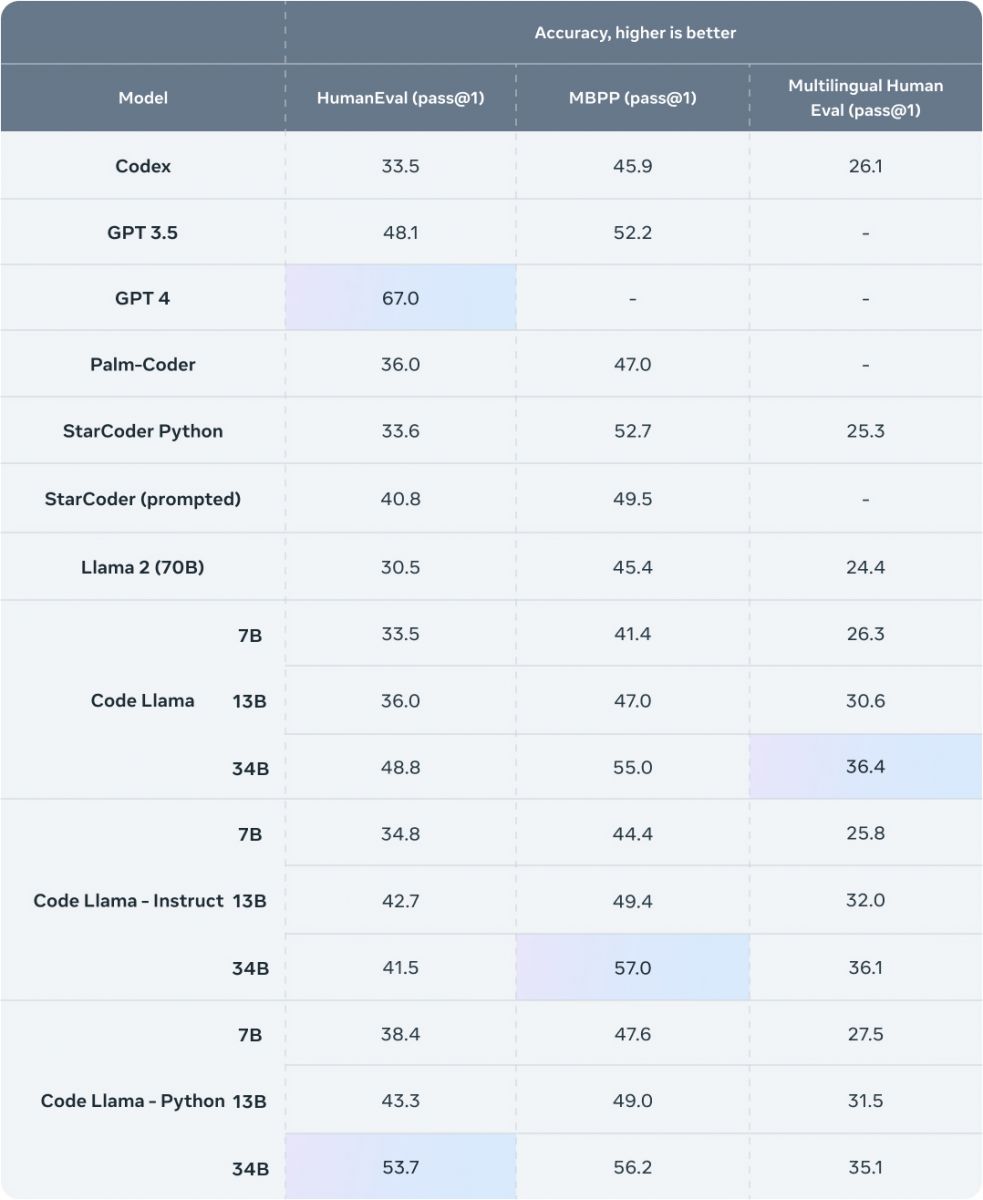
Meta使用目前两种流行的程序开发基准来测试Code Llama模型,分别是HumanEval与MBPP(Mostly Basic Python Programming),HumanEval可以测试模型根据文件字符串完成代码的能力,而MBPP则可以测试模型根据描述编写代码的能力。
经测试,Code Llama程序开发的能力优于其他开源,且同样针对代码生成的大型语言模型,Code Llama 340亿参数模型版本,在HumanEval得分53.7%,而在MBPP的得分则是56.2%,较其他开源解决方案更高。