


NVIDIA公布了H100于MLPerf v3.1推论测试的成绩,并说明GH200 Grace Hopper Superchip的效能最高能较H100提升17%。
MLPerf v3.1依然全勤
NVIDIA公布MLPerf最新版本v3.1推论测试的成绩,新版测试主要的变动为更新推荐系统测试,以及新增GPT-J 6B测试,H100依然提交了所有项目的成绩。
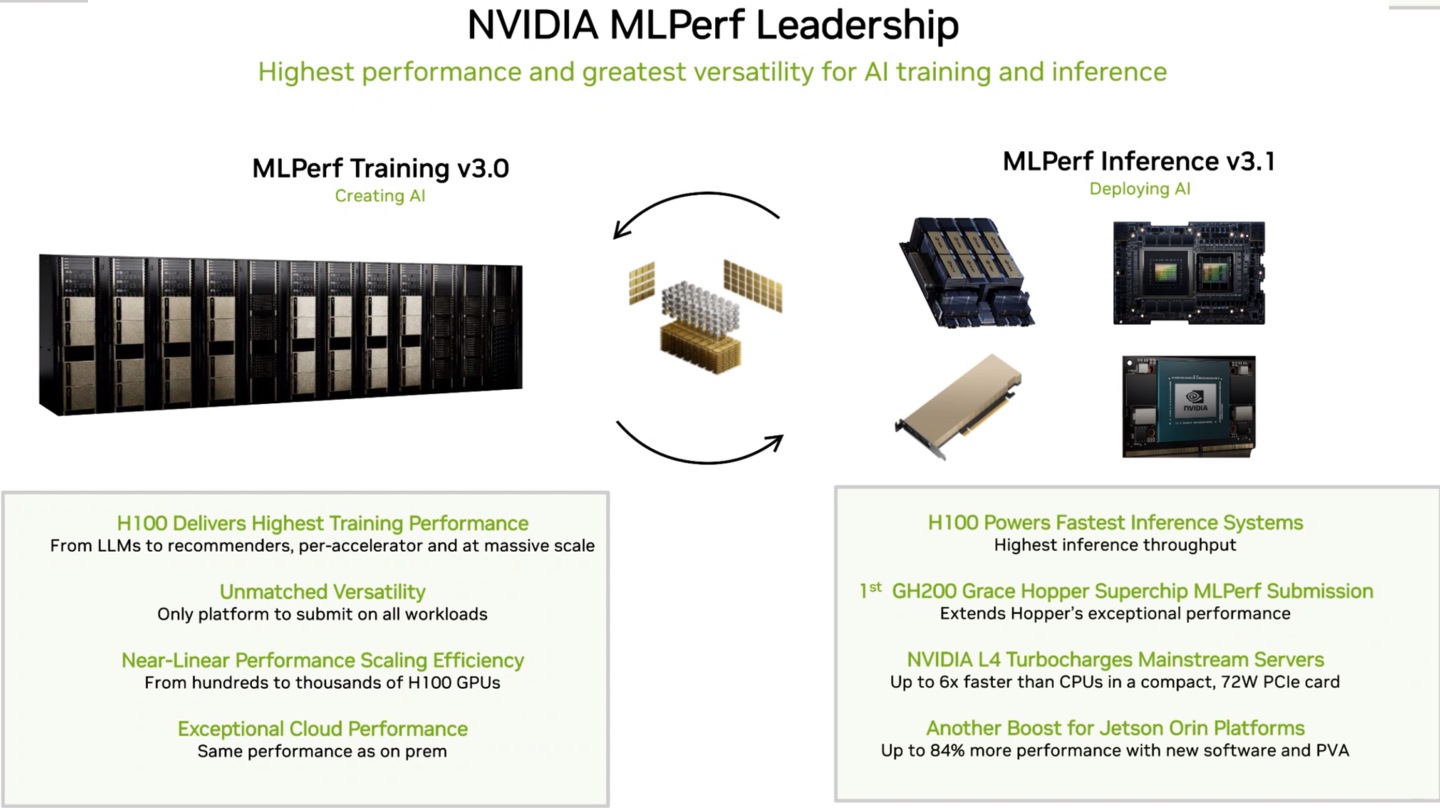 ▲ NVIDIA在说明会中强调了MLPerf v3.1推论测试的变动,以及GH200、L4、Jetson Orin等设备的测试成绩。
▲ NVIDIA在说明会中强调了MLPerf v3.1推论测试的变动,以及GH200、L4、Jetson Orin等设备的测试成绩。
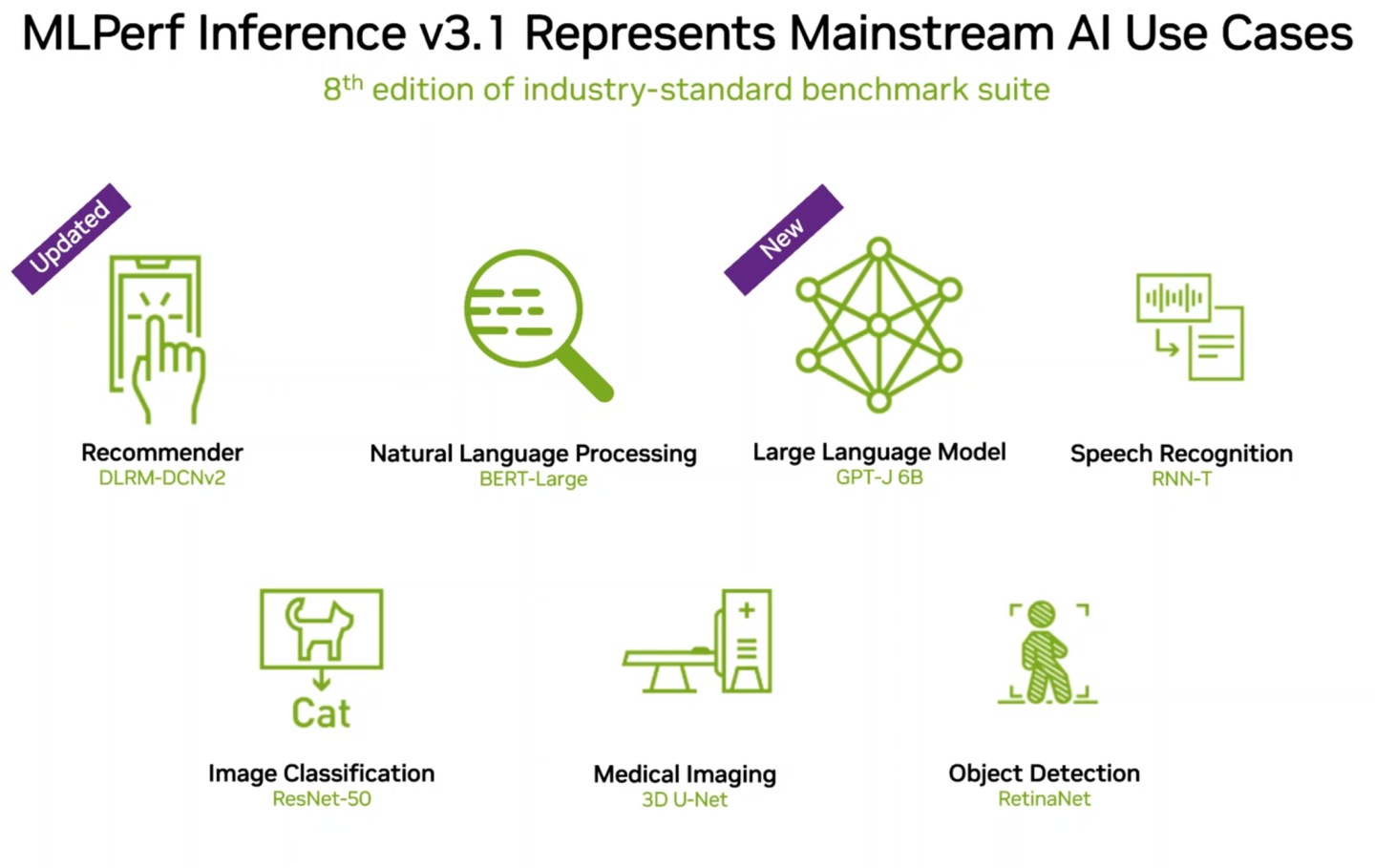 ▲ MLPerf v3.1主要是更新推荐系统测试使用的DLEM-DCNv2,以及新增GPT-J 6B测试。
▲ MLPerf v3.1主要是更新推荐系统测试使用的DLEM-DCNv2,以及新增GPT-J 6B测试。
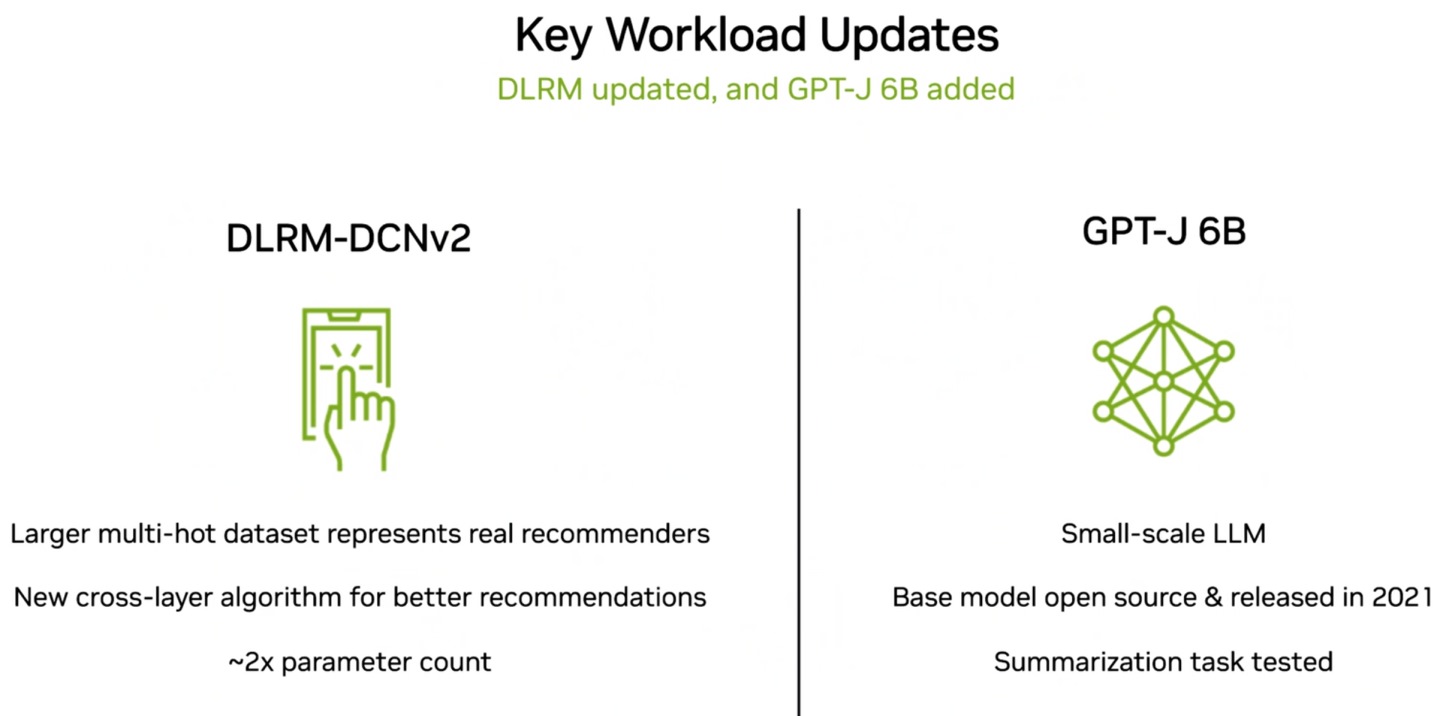 ▲ DLEM-DCNv2具有新的算法,能提供更高的推荐参数量(Recommendations Parameter Count),GPT-J 6B则是具有60亿组参数的「较小型」大型语言模型(GPT-3具有1,750亿组参数)。
▲ DLEM-DCNv2具有新的算法,能提供更高的推荐参数量(Recommendations Parameter Count),GPT-J 6B则是具有60亿组参数的「较小型」大型语言模型(GPT-3具有1,750亿组参数)。
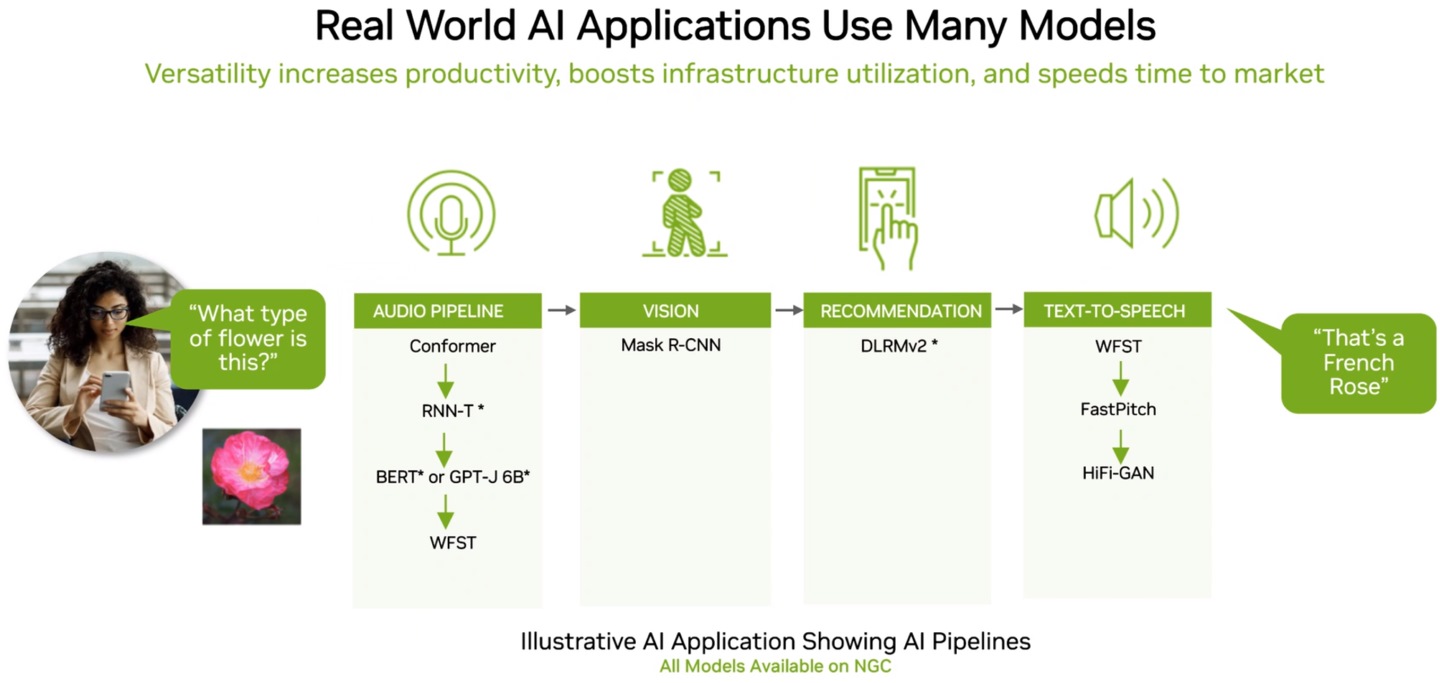 ▲ NVIDIA表示能提交所有测试成绩相当重要,代表自家产品有能力胜任多样的AI运算需求。 举例来说,通过语音询问AI摄影机拍到的花是什么品种,并让结果同样以语音输出,就需要用到语音识别、自然语言处理、影像识别、推荐系统、语音合成等AI管线。
▲ NVIDIA表示能提交所有测试成绩相当重要,代表自家产品有能力胜任多样的AI运算需求。 举例来说,通过语音询问AI摄影机拍到的花是什么品种,并让结果同样以语音输出,就需要用到语音识别、自然语言处理、影像识别、推荐系统、语音合成等AI管线。
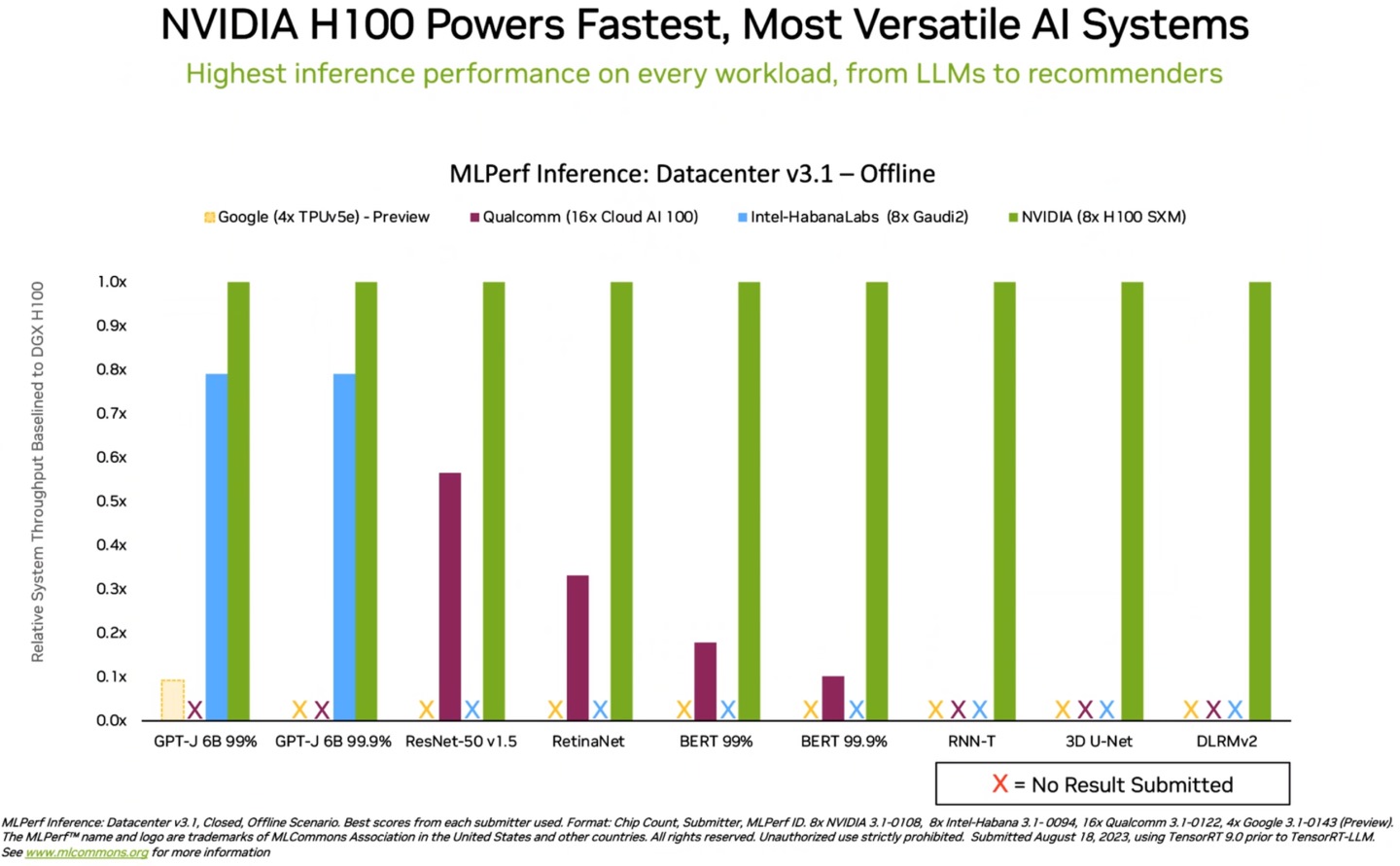 ▲ H100在MLPerf v3.1的成绩领先Google、Qualcomm、Intel等对手。 其中打叉的项目为没有提交成绩。
▲ H100在MLPerf v3.1的成绩领先Google、Qualcomm、Intel等对手。 其中打叉的项目为没有提交成绩。
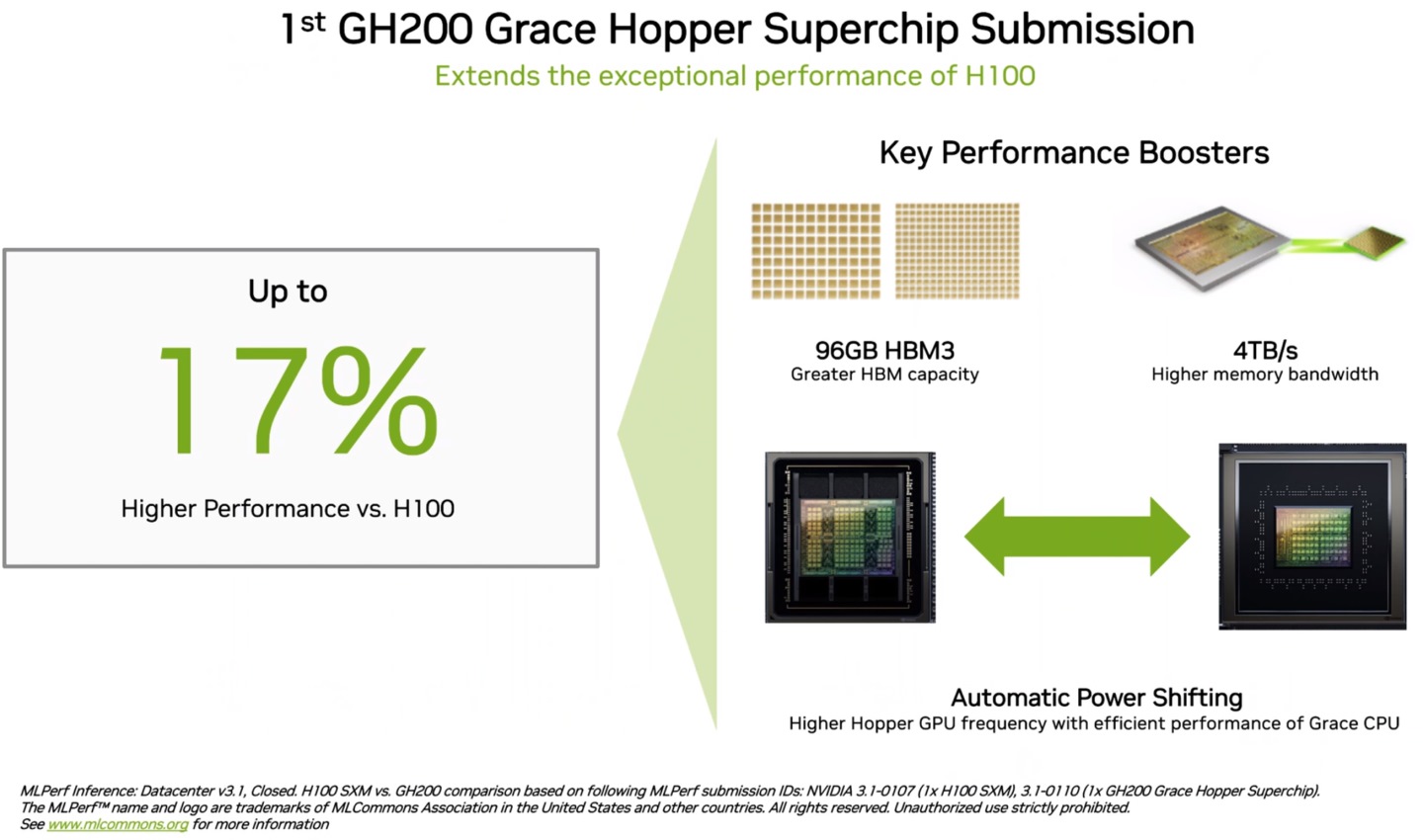 ▲ GH200具有更大容量的内存,也支持处理器与GPU之间的动态电力调配,效能最高能较H100提升17%。
▲ GH200具有更大容量的内存,也支持处理器与GPU之间的动态电力调配,效能最高能较H100提升17%。
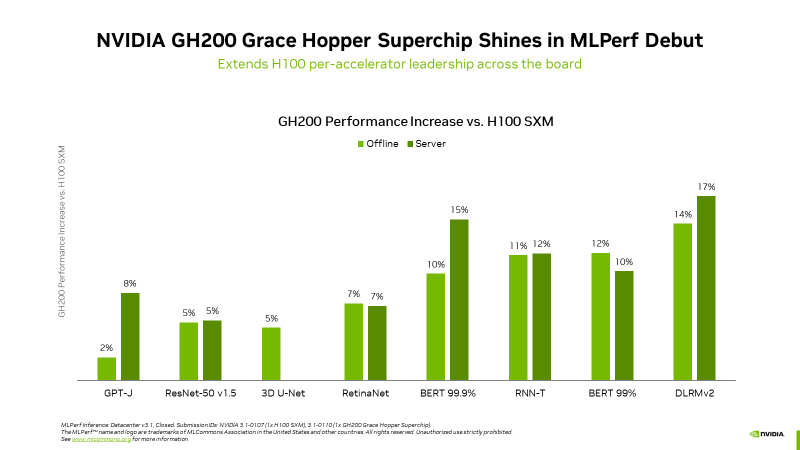 ▲ 根据NVIDIA提供的数据,GH200在多项测试项目领先H100的幅度介于2%~17%之间。
▲ 根据NVIDIA提供的数据,GH200在多项测试项目领先H100的幅度介于2%~17%之间。
 ▲ L4是单槽、半高的PCIe接口AI运算卡,且不需额外插电,适合安装在任何现有服务器。 它也一样完成所有MLPerf测试项目,且能提供6倍于x86处理器的推论效能,若是处理影像相关运算,更是能受益于内置的专属媒体引擎,将效能增益拉到120倍之谱。
▲ L4是单槽、半高的PCIe接口AI运算卡,且不需额外插电,适合安装在任何现有服务器。 它也一样完成所有MLPerf测试项目,且能提供6倍于x86处理器的推论效能,若是处理影像相关运算,更是能受益于内置的专属媒体引擎,将效能增益拉到120倍之谱。
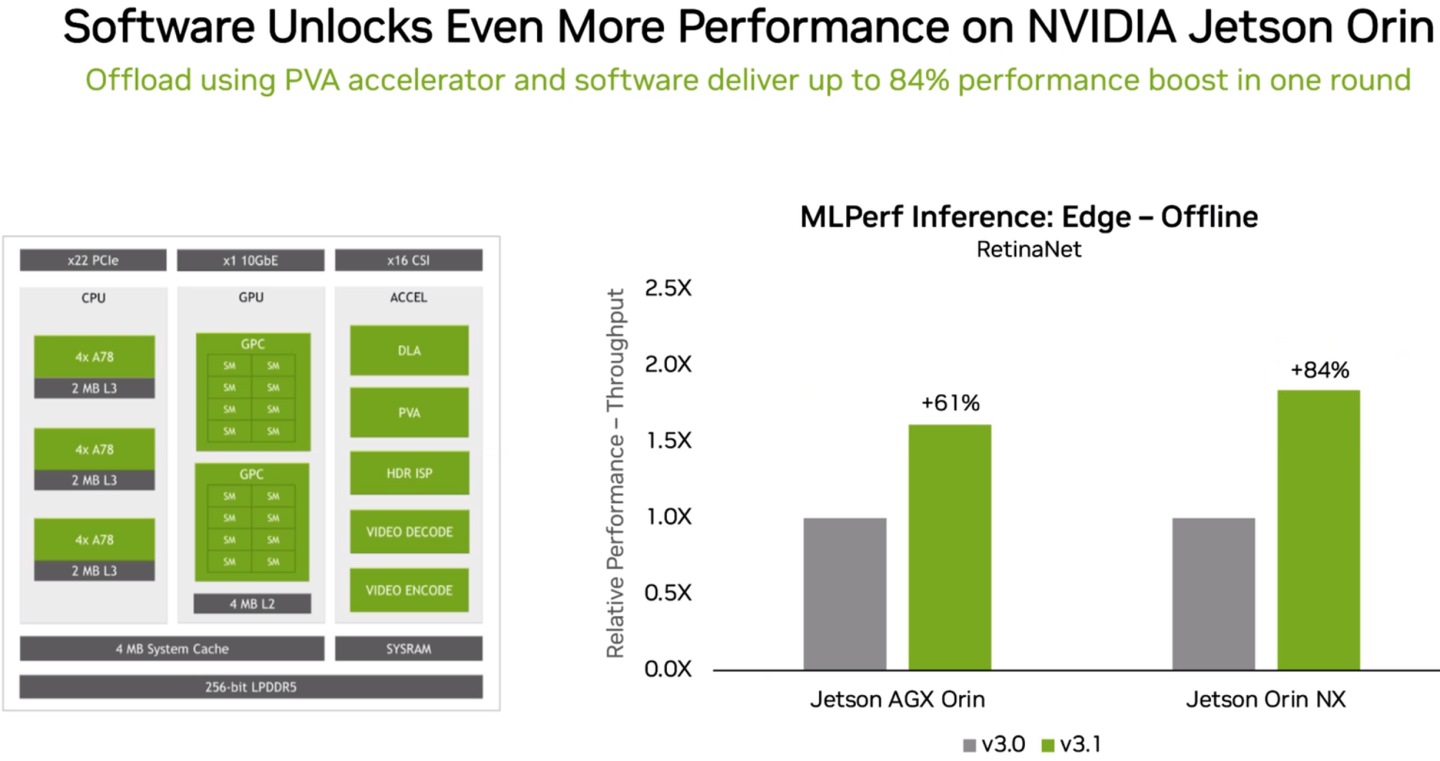 ▲ Jetson Orin系列运算平台则是通过软体优化,带来61%至84%的效能提升。
▲ Jetson Orin系列运算平台则是通过软体优化,带来61%至84%的效能提升。
GH200将Grace处理器与Hopper GPU整合为单一超级芯片,具有容量更大的内存,带宽也更大,并且能在处理器和GPU之间自动调节电力,提高整体效能表现。