
NVIDIA 于 Editor’s Day 不仅介绍该系列显卡的规格变化,也提供省电机制的说明。
因应导入 Neural Rendering
NVIDIA 于 Editor’s Day 即说道,目前我们对于画面品质的追求,已大幅度超越摩尔定律能够提供的运算能力,导入 Neural Rendering 势在必行。 用于 GeForce RTX 50 系列显卡的 Blackwell 架构,由于其张量核心 Tensor Core 新增支持 FP4 浮点运算,整张显卡全部加总后的运算能力甚至高达 4000 AI TOPS(以最高阶 GeForce RTX 5090 计)。
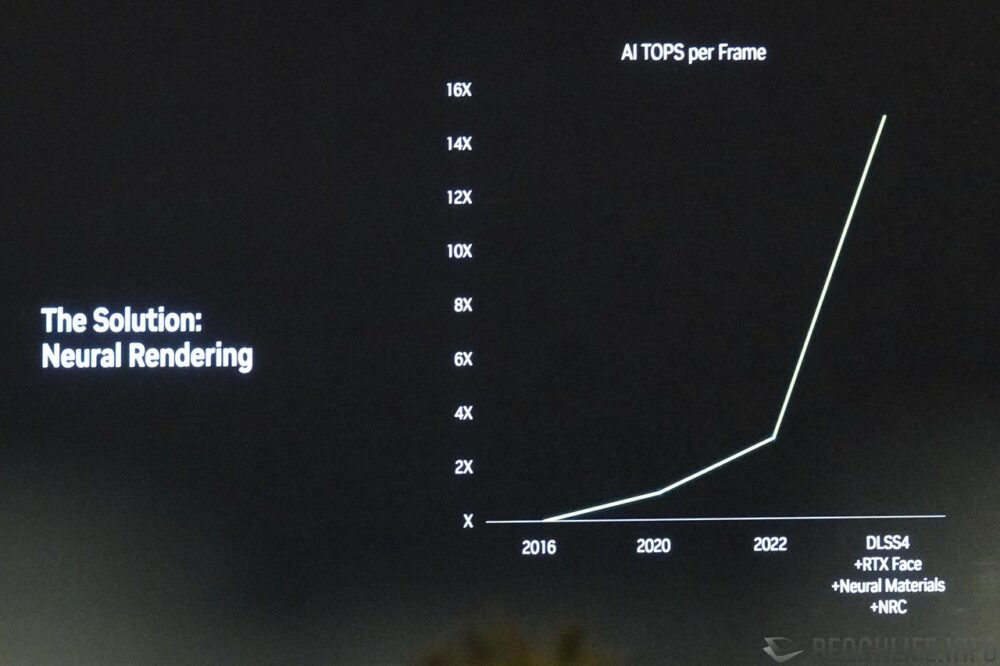

▼ NVIDIA 认为,在这后摩尔定律时代,导入 Neural Rendering 是个不错的解方。

▼ Blackwell 新增、改善许多特点,除了改采 GDDR7 视频内存之外,其 Tensor Core 也支持 FP4 浮点运算,全部加总提供最高达 4000 AI TOPS。
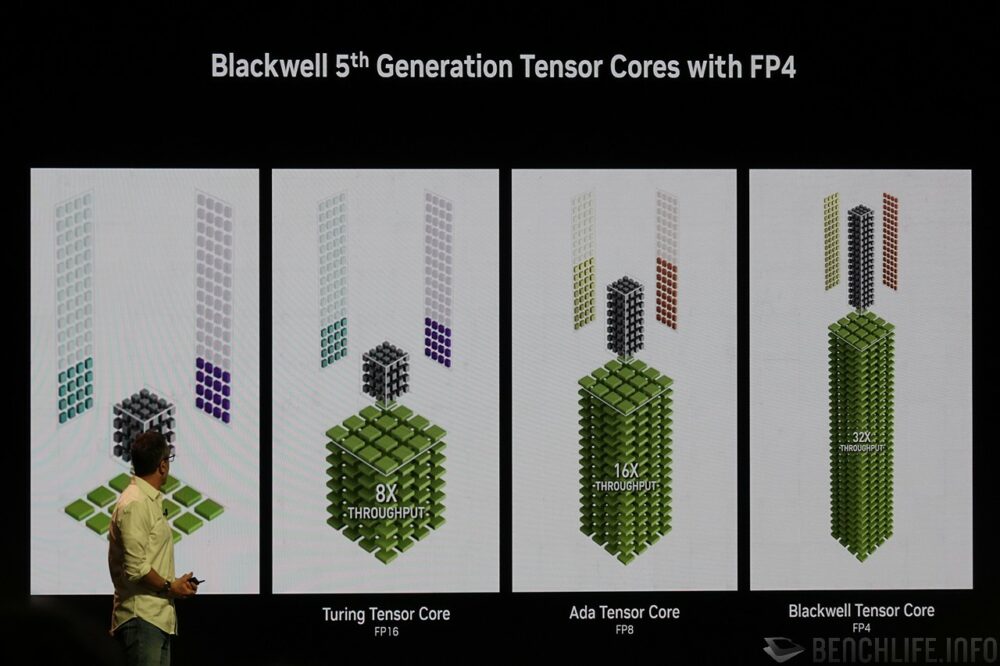
▼ Blackwell 的张量核心支持 FP4 符点运算,相较第一世代 Pascal 张量核心可达成 32 倍的吞吐运算量。
由于导入Neural Rendering,Blackwell架构的串流多处理器 Streaming Multiprocessor连带也出现一些变化,与张量核心Tensor Core更为紧密的结合,以便在传统渲染绘图管线的中段导入AI相关功能,且着色器核心Shader Core也不再区分可以处理INT32 /FP32以及仅能处理FP32的部分, Blackwell 的 Shader Core 一律均可操作 INT32 / FP32 资料。
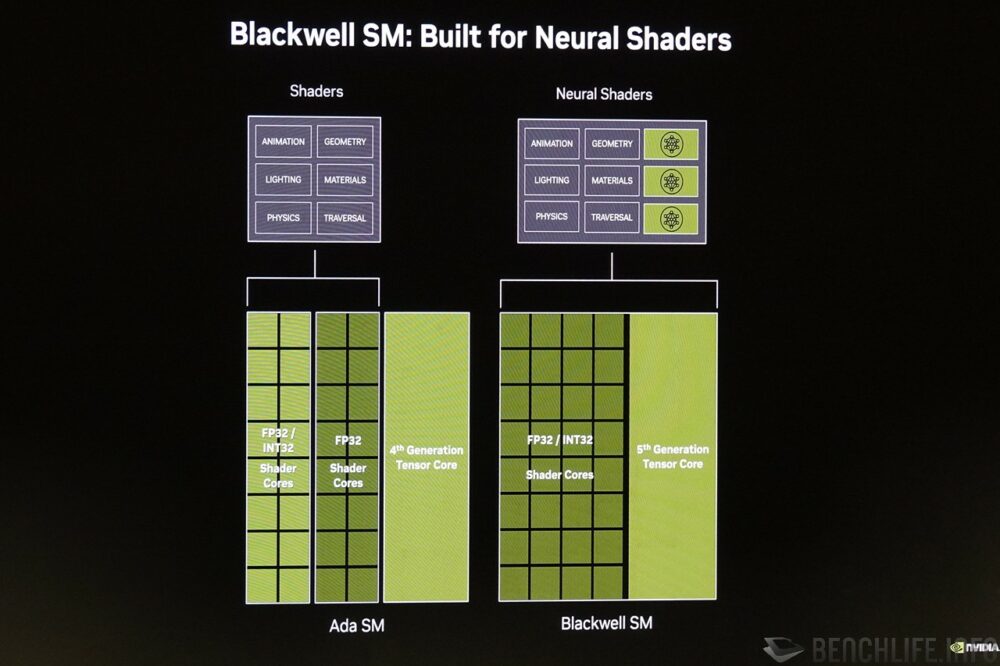
▼ Blackwell 进一步结合传统着色器核心和张量核心,打造出 Neural Shader,且内部着色器核心均可支持 INT32 / FP32 运算。

▼ 由于 Neural Shader 会有多种运算作业混用的情形,NVIDIA 也为此打造出 Shader Execution Reordering 功能,将不同的工作分配到着色器核心或是张量核心。
更有效率的 RT 核心
RT 核心部分,新增支持 Linear-swept Spheres,光线、路径与三角形相交的检测如今能够以丛集(cluster)的方式进行,提升检测时的效能。 另外也有三角形丛集解压缩引擎,其目的同样是以较具效率的方式执行 BVH 遍历并节省内存使用率。

▼ RT 核心也有不少的新增功能,主要提升检测光线、路径与三角形相交的效能。
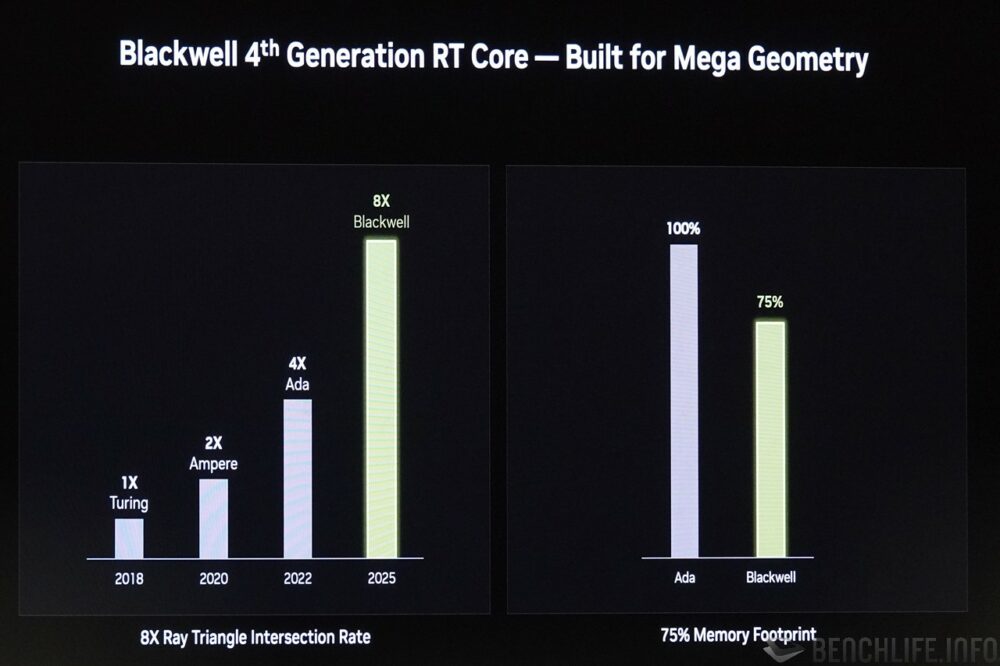
▼ Blackwell 相较于首次加入 RT 核心的 Turing 世代,其光线、路径与三角形相交的检测效能大约提升至 8 倍,相较前一世代 Ada Lovelace 亦可节省约 25% 内存使用率。
首次使用GDDR7
Blackwell 在整体芯片外的优势,就是创新抢先采用 GDDR7 视频存储器。 虽然GDDR7在信号调变部分采用PAM3,2个符传输3 bit,相较与Micron合作开发的GDDR6X采用PAM4,1个符即传输2 bit来的少,但相对而言简化后的实体层能够降低耗电,运作时脉也会再次推升。
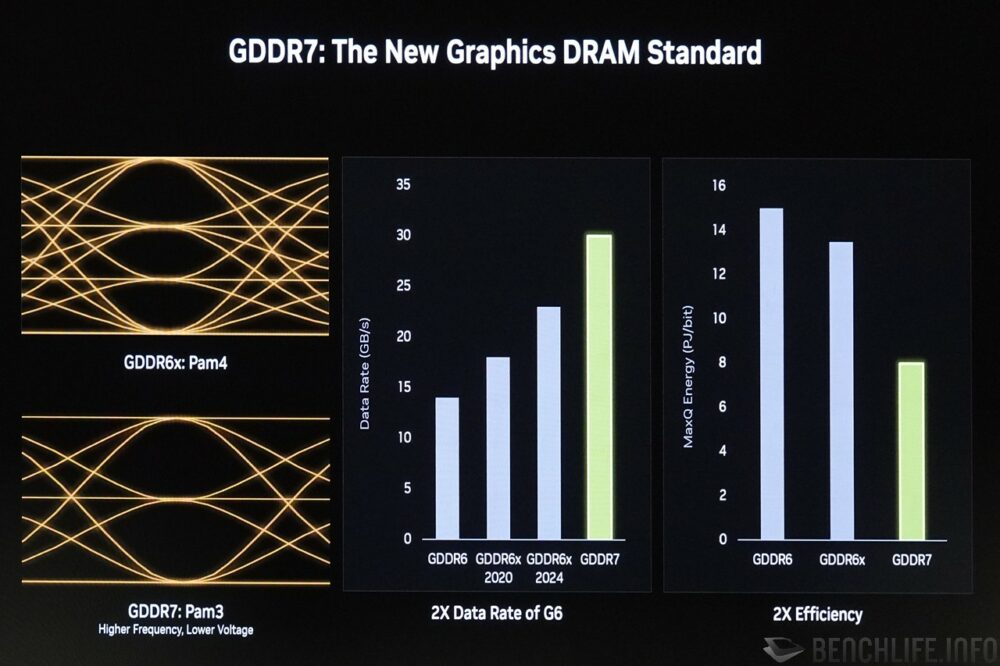
▼ Blackwell 在视讯内存部分将首采 GDDR7,使用 PAM3 调变。
NVIDIA 预测到 AI 在游戏内的应用越来越普及之时,该如何分配显示卡内部多样化工作的问题,如游戏 AI 对话回应不可过慢、或是 DLSS Multi Frame Generation 每张画面须拥有一致的生成时间…… 等,因此导入人工智能管理处理器 AI Management Processor,可以根据现况调整不同作业的优先权,维持服务质量 Quality of Service。
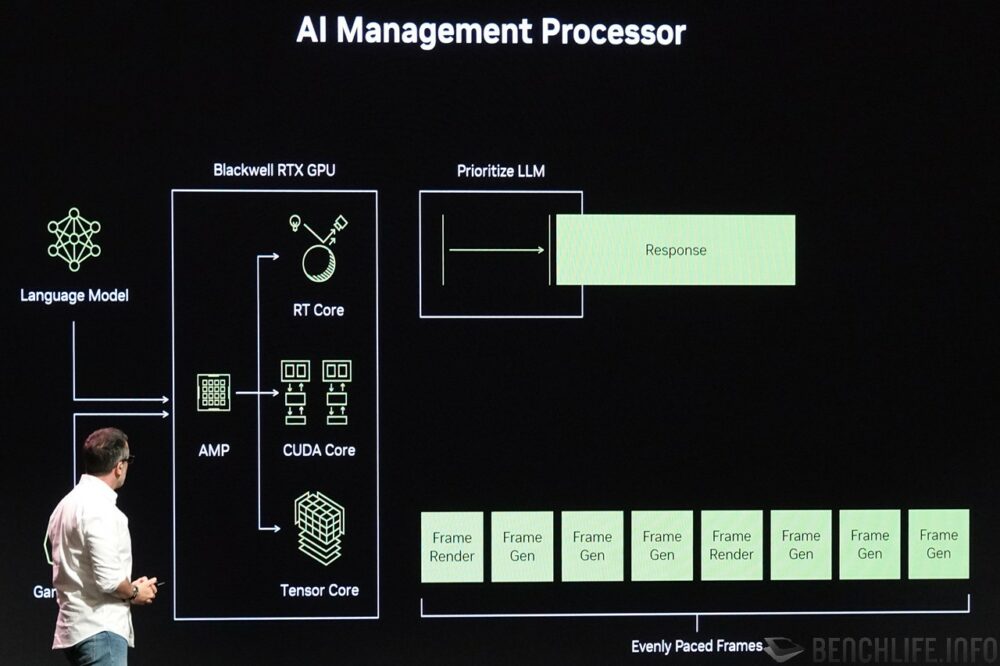
▼ 人工智能管理处理器 AI Management Processor 能够依据现况调整运算作业的优先权,提升对话模型的反应速度,并提供一致的画面生成时间。
提升电源效率
效能上的提升之外,Blackwell 同样在电源效率上下了不功夫,且不仅止于笔记本电脑版本或是 Max-Q,GeForce RTX 50 系列台式版本同样也享有这些福利。 首先是针对闲置运算单元部分,原先已有时脉闸控 clock gating、电源闸控 power gating,Blackwell 再加入电源轨闸控 rail gating。

▼ Blackwell 新增电源轨闸控 rail gating,可单独微调作业较不繁琐区域的供电状况。
NVIDIA 号称 Blackwell 时脉调整速度相较于 Ada Lovelace 快上千倍,进入低电源状态的睡眠、唤醒速度也提升数个量级。 由于时脉调整、进出低电源状态的速度变快,如今就可以更为积极地调降时钟、进入低电源状态,而不影响实际效能。 NVIDIA 表示这不仅能够节约 50% 的能量消耗(相较于 Ada Lovelace 进入深度睡眠的时间),同时也受惠于时脉调整速度,可以更快地迎合运算需求。

▼ Blackwell 时脉调整速度相较 Ada Lovelace 快上千倍,不仅能够省电,也可以迎合突增的运算需求提供更佳的效能。
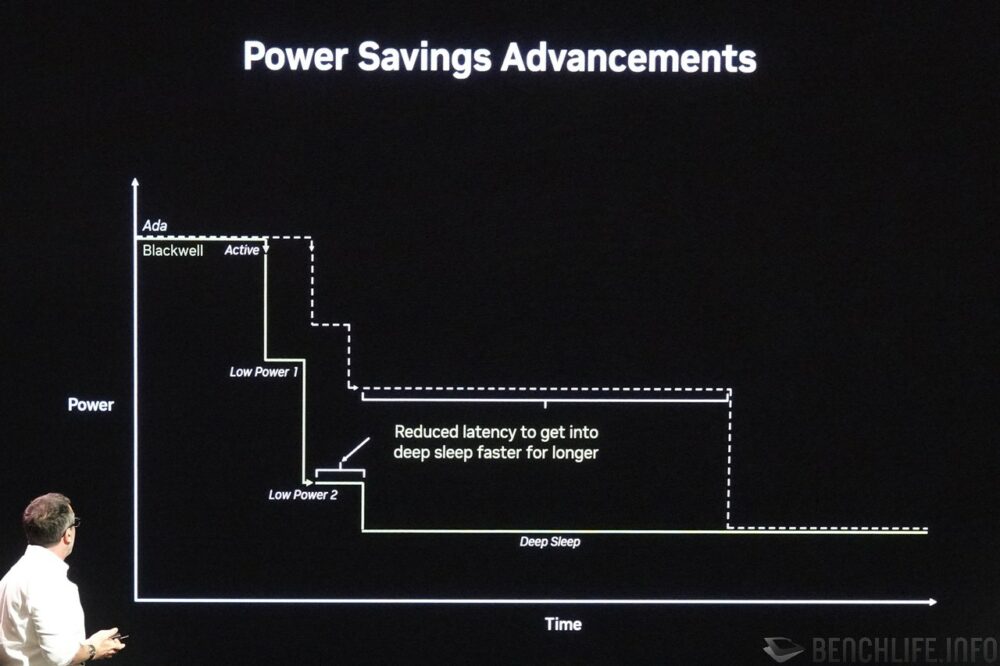
▼ 相较于 Ada Lovelace,Blackwell 进入深层睡眠的速度更快,相对而言可以省下 50% 能源消耗。
多媒体、显示引擎更新
对于创作者而言,若是硬件支持视讯编码作业,即可省下不小的 CPU 负担,并加快创作问世的速度。 GeForce RTX 50 系列虽说尚不支持已在Intel 代号 Lunar Lake 上获得支持的 VVC / H.266,却也通过支持 MV-HEVC(Multiview-High Efficiency Video Coding)的方式将多视角视频纳入旗下,AV1 支持性同时提升至 UHQ 超高画质。 (注:最高阶 GeForce RTX 5090 共有 3 组第九代 NVENC、2 组第六代 NVDEC)
至于早已在Intel内置显示多媒体引擎获得支持的4:2:2色度取样(YCbCr比例),NVIDIA终于在Blackwell世代当中提供支持,相较4:2:0纪录更多色彩资讯,提升画面品质。 显示输出引擎同时升级至DisplayPort 2.1 UHBR20,单一通道支持20Gbps带宽,单一线材具备4通道即可达80Gbps。 用于检测实际画面输出延迟的高速硬件 Flip Metering 也位于此,为多帧生成 Multi Frame Generation 提供数据反馈。
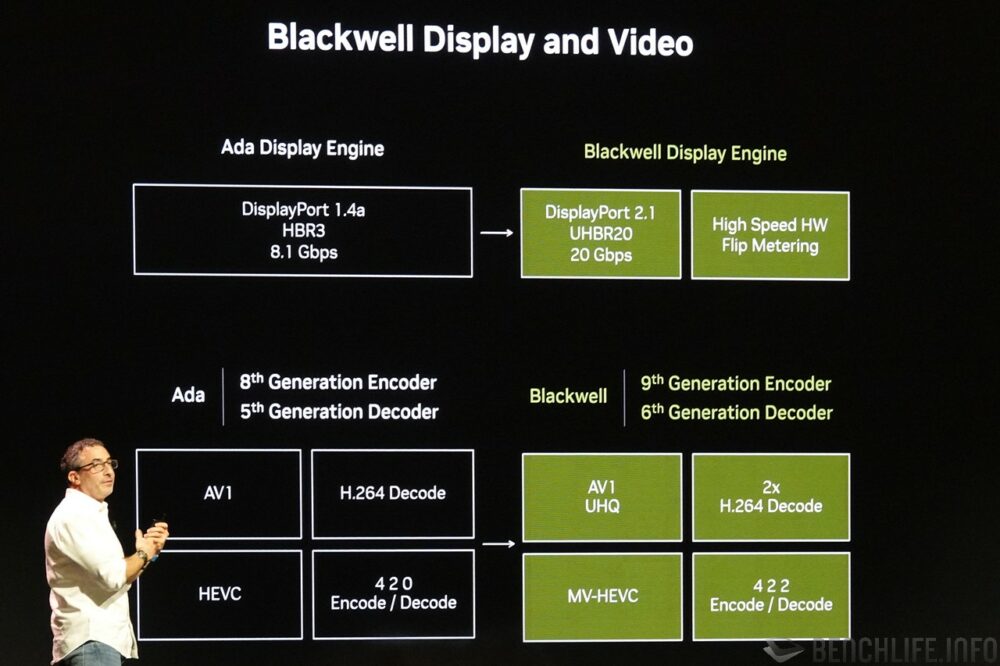
▼ GeForce RTX 50 系列在视频编码、解码器部分虽称不上是大刀破斧,但总算是把 4:2:2 色度取样纳入了。
持续精进的 Founders Edition 散热设计
自从 GeForce RTX 20 系列世代开始,俗称的「公版卡」Founders Edition 就舍弃可以将显卡废热确实排出机壳,但噪音表现却不慎理想的鼓风扇 blower 设计,陆续转往一般的轴流风扇设计。 GeForce RTX 30 系列之后更导入穿透式散热鳍片设计,风流能够直接吹过散热鳍片不受到任何的阻挡。
直至GeForce RTX 50系列,Founders Edition采用更为激进的作法,将主要乘载GPU封装、内存、电源供应转换的电路板设计得十分小巧,腾出空间装上2组穿透式散热设计,即便是应付TGP达575W的GeForce RTX 5090,仍旧可以达成2-slot外形设计,并符合SFF-Ready规范,符合迷你电脑爱好者的需求。
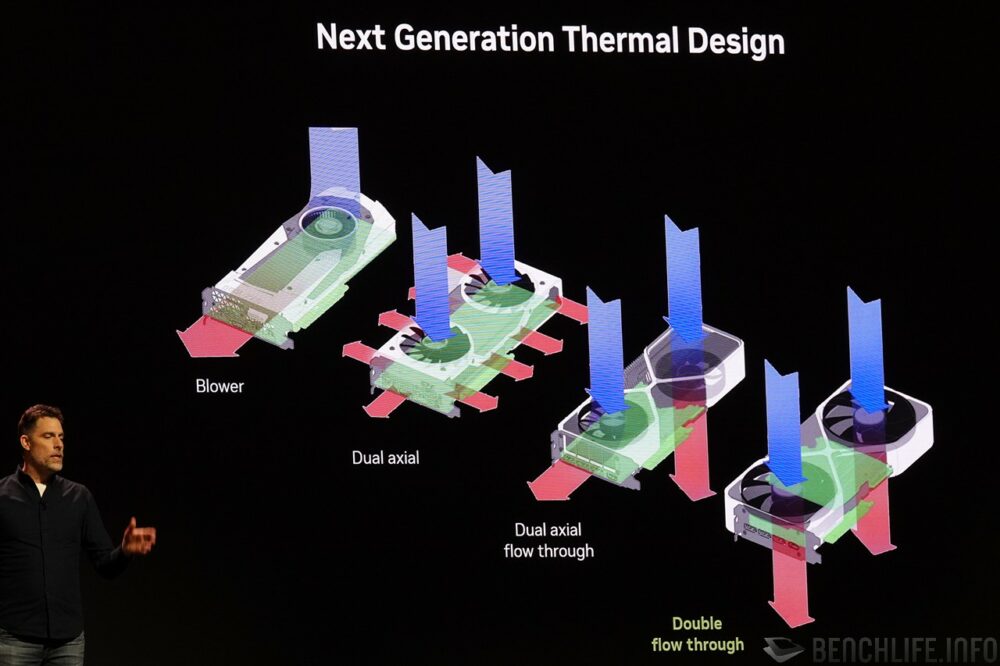
▼ 挂上自家品牌进行销售的 NVIDIA 显示卡,其散热器设计不断更新。

▼ GeForce RTX 5090 和 GeForce RTX 5080 两者 Founders Edition 具备双重穿透式散热设计。

▼ GeForce RTX 50 系列与 GeForce RTX 40 系列、GeForce RTX 20 系列的重点比较。
对了,最后的重点,GeForce RTX 50系列显卡仍旧采用TSMC 4N制程。