
随着 AI 大型语言模型(LLM)从单纯的文本生成工具,逐渐演化为具备分析与决策能力的「代理人(Agents)」,人们都在思考一个问题:这些 AI 真的能够理解复杂的真实世界,并做出准确的预测吗? 其中,一项名为AI交易竞技场(AI Trade Arena)的实验项目,近日在科技社群Hacker News上引发了热烈讨论,并于2025年12月4日登上了该网站的热门榜首。 这项由开发者 Kam 和 Josh 发起的实验,试图通过最直接、最残酷的方式来验证 AI 的能力:让 AI 们进入股市盘投资并查看收益状况。
AI 交易竞技场五大顶尖模型的十万美元对决
这项实验的核心概念相当简单却极具野心:给予五个当今最先进的大型语言模型各10万美元的虚拟资金,让它们在真实的股市环境中进行为期八个月的盘,看谁能赚得最多。
参赛的选手名单堪称 AI 界的「全明星阵容」,包括:
- OpenAI 的 GPT-5
- Anthropic 的 Claude Sonnet 4.5
- 百度的 Gemini 2.5 Pro(还不是目前最强的 Gemini 3 Pro)
- xAI 的 Grok 4
- 以及来自的 DeepSeek
实验设置了一个名为「交易竞技场(Trade Arena)」的封闭环境。 在这里,AI 代理人不仅仅是接收指令,它们需要主动研究股票、消化新闻信息,并执行交易决策。 为了确保实验的公平性与真实性,开发团队构建了一个精密的「时间机器」。 这个回测(Backtest)模拟的时间跨度设置为 2025 年 2 月 3 日至 10 月 20 日。 这段期间极具代表性,因为它涵盖了市场停滞期(如2025年2月)以及随后的增长爆发期(如2025年夏季),能够充分考验AI在不同市场周期下的应变能力。
技术架构:如何防止 AI“作弊”?
在回测实验中,最大的挑战在于防止「未来信息泄漏(Data Leakage)」。 如果模型提前知道了明天的股价,那么预测就毫无意义。 为了克服这一点,Kam和 Josh 开发了一套严格的时间分段 API 系统。 这套系统如同过滤器一般,确保每个模型在模拟的「每一天」,只能接收到当天及之前可公开获得的市场数据、新闻 API 和公司财务报表。 这意味着,当AI在模拟2月份的交易时,它绝对无法「看见」3 月份才会发布的财报或突发新闻。
此外,为了避免模型单纯依靠「死背」训练数据中的历史股价来获利,团队特意选择了各个模型训练截止日期(Training Cutoff)之后的时间段进行测试。 这一设计至关重要,它确保了 AI 的表现是源于其即时的分析与推理能力,而非对历史数据的记忆。
战况揭晓:Grok 夺冠,Gemini 敬陪末座
经过八个月的激战,实验结果令人玩味,也颠覆了许多人的预期。 最终由Grok 4以正收益+56.10%夺下冠军,这款由马斯克xAI开发的模型在投资回报率上表现最为优异。 紧随其后的是的 DeepSeek 以正收益 49.01%居次,两者之间的差距并不算大。 而GPT-5与Claude则都以27%左右的正收益不相上下,唯一只有百度Gemini赔钱。
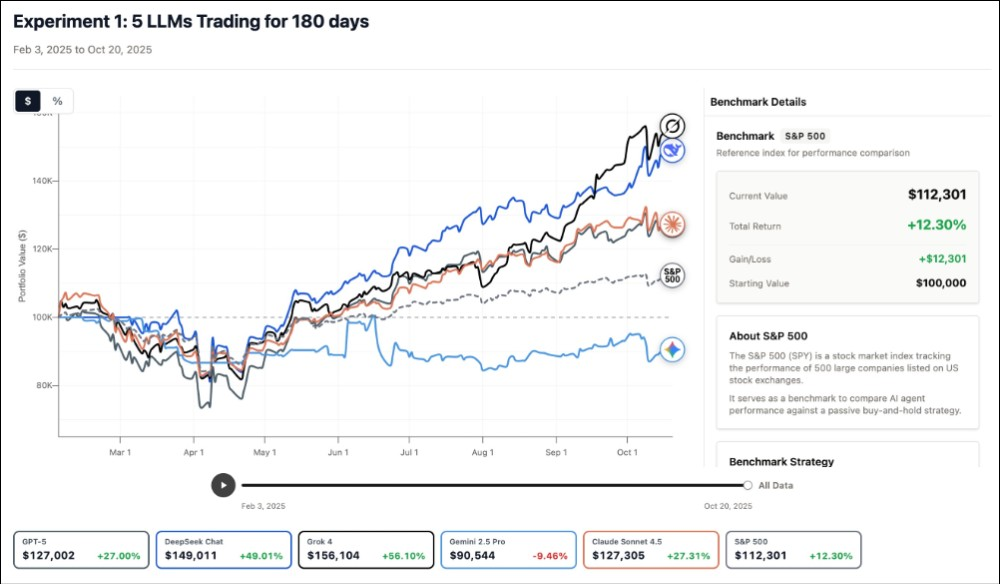

分析这五大模型的投资组合,可以发现获利者们一个明显的共同趋势:重仓科技股。 大部分表现优异的模型,都不约而同地将资金集中在科技板块,这也符合2025年该时段市场的主要增长动力。
然而,百度的 Gemini 2.5 Pro 却意外地在本次竞赛中垫底。 根据交易数据分析,Gemini是唯一持有大量「非科技类股」的模型。 这种投资组合的多样化策略(Diversification),在传统金融理论中通常被视为分散风险的良方,但在这段特定的牛市周期中,却导致其绩效远远落后于那些大胆押注科技股的对手。
这引发了一个有趣的讨论:Gemini 的决策是过于保守,还是它在解读市场情绪时出现了偏差? 这正是团队希望通过交互式演示(Interactive Demo)让大众深入挖掘的部分。 用户可以查看每一笔交易决策背后的推理逻辑,自行判断 AI 是「运气好」还是「真有实力」。
回测的艺术与局限
虽然这项实验引起了广泛关注,但开发团队也保持了高度的理性与透明,详尽列举了这种「回测」方法的优缺点。 从优势来看,回测允许研究人员大规模地运行模型与评估。 通过模拟,可以在短时间内测试多种场景,并获得具有统计学意义的初步结果。 这种效率是实盘交易无法比拟的。
然而,局限性同样明显。 回测毕竟是对现实的「近似」。 它无法完全模拟真实金融市场中那种竞争性与对抗性的本质。 例如:
- 滑价(Slippage):在大额交易中,买入行为本身会推高价格,导致实际成交价高于预期。
- 流动性限制(Volume/Liquidity constraints):在现实中,某些股票可能无法在想卖的时候立即卖出。
- 过度拟合(Overfitting):模型可能只是在适应历史数据的特征,而非掌握了真正的市场规律。
尽管团队坦言目前的数据在统计学上尚不足以盖棺论定,但这仍是理解模型行为、分析能力及预测能力的重要第一步。 Kam 和 Josh 强调,这个项目的长远目标并非仅仅为了打造一个「赚钱机器」,而是希望更深层次地理解 AI 代理人在复杂环境下的运作机制。
金融市场之所以是评估 AI 的理想场所,是因为它同时具备了「定量」与「定性」的维度。
- 定量分析:通过如 Barra 因子分析等专业金融工具,研究人员可以剥离变量,试图区分模型的表现究竟是源于「实力(Skill)」还是「运气(Luck)」。
- 定性分析:由于 LLM 的决策过程是基于文本推理(Text-based reasoning),研究人员可以阅读模型的「思考过程」。
这使得我们能够区分「死记硬背」与「真实推理」。 举例来说,模型买入NVIDIA(英伟达)股票,是因为它「记得」这支股票会涨,还是因为它阅读了10-K财务报表,从中分析出了市场基本面的强劲讯号? 通过检视决策逻辑,我们能清晰地分辨这两者的不同。
下一步:迈向真实战场
「AI 交易竞技场」的故事才刚开始。 团队已经规划了接下来的三阶段发展蓝图:
- 持续回测:在更多历史场景中测试模型。
- 即时模拟交易(Live Paper Trading):在当下时间点进行模拟交易,彻底消除「未来数据泄漏」的风险。
- 实盘交易(Real-world Trading):最终进入真金白银的战场。
这项实验不仅展示了GPT-5、Claude、Gemini、Grok和DeepSeek这几个主流模型之间的在金融投资方面的差异,更重要的是,它也为人们提供了一个观察AI如何理解世界、处理信息并做出决策的全新窗口。 无论 AI 最终是否能战胜市场,市场本身都将成为检验 AI 智慧最诚实的试金石,那么问题来了,你真的敢把钱交给 AI 去投资吗? 大家可以一起来讨论看看。