
重点新闻(0331~0406)
GPT-4 Vicuna 大型语言模型
美顶尖大学联手用300美元训练出类GPT-4的大型模型Vicuna
在斯坦福大学用600美元打造ChatGPT复制版的模型Alpaca后,包含CMU、加州大学伯克利分校、斯坦福大学和加州大学圣地亚哥分校在内的几间美国顶尖大学,共同打造并开源一款类GPT-4的大型语言模型Vicuna,具130亿参数,产出的回答可达等同ChatGPT九成的品质,且比Meta的LLaMA和斯坦福大学的Alpaca还要好 ,但训练成本才300美元左右。
Vicuna的训练数据来自微调后的LLaMA,以及从ShareGPT收集的对话。 ShareGPT是一个让用户分享自己与ChatGPT对话的网站,团队在该网站收集了7万多个对话,并强化了Alpaca产出的训练脚本,来加强模型对多轮对话和长序列文字的能力。 他们在1天内,以8个A100 GPU和PyTorch FSDP完成Vicuna的训练,后来,团队也设置80个多元的问题,让不同模型来回答问题,并以GPT-4来评估这些模型的回答,包括Vicuna、Alpaca、ChatGPT和LLaMA。 其中,Vicuna的总分是ChatGPT的92%,且生成的答案比Alpaca还要详细、更有结构。 但团队指出,Vicuna在代码生成和基本数学问题的表现仍有待加强,且安全性也需进一步强化。 (详全文)


UC Berkeley Koala 大型语言模型
UC Berkeley打造研究查询专用对话模型,打下LLM私有化基础
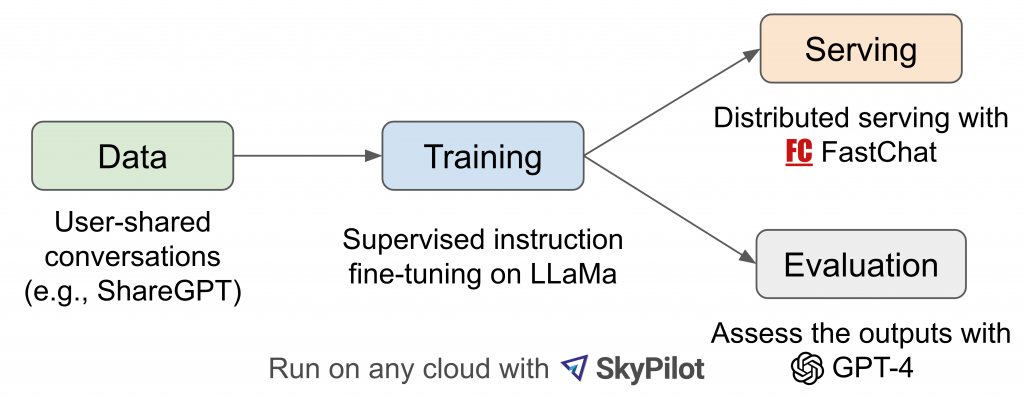
加州大学柏克莱分校(UC Berkeley)最近发表一款对话式大型语言模型Koala,可回答研究相关的查询问题,甚至模型产出的多数答案,比斯坦福大学的Alpaca模型要好,且至少一半的答案质量与ChatGPT相当。
进一步来说,团队先是收集网络上的对话数据,包括来自公开数据集和高质量的生成式AI对话,如ChatGPT/ShareGPT、Alpaca等,来微调Meta的LLaMA模型,并以此来训练Koala模型。 他们从ShareGPT收集的对话有6万个示例,后来精简为可用的3万个,并采用HC3英语语料库中人类与ChatGPT的问答共8万7千多例,来训练Koala。 不只如此,他们也从Alpaca、开放式数据集OIG、OpenAI WebGPT等处收集高质量的训练数据,并打造70亿参数和130亿参数版本的Koala。
后来,团队通过Amazon Mechanical Turk群众外包平台来评估Koala和Alpaca的效能,也就是让100位用户评比哪种回答较好,发现近一半的回答评为比Alpaca好,近70%则与Alpaca相当或比它好。 团队指出,虽然Koala的安全性和一致性仍有很大的进步空间,但与其他LLM相比,这种采用少量高质量数据训练而成的模型,效能与千亿参数的LLM相当,等于提供一种LLM私有化的发展基础,也就是能自行训练出等同于科技巨头的大型语言模型。 (详全文)
Google ViT-22B 机器人
Google将ViT扩大到220亿参数,还结合LLM来执行机器人任务
Google在3月底发表一篇博客文章,说明团队如何将Transformer计算机视觉模型ViT扩展至220亿个参数,也就是ViT-22B,比之前同类型最大模型ViT-e大了5.5倍(原40亿参数)。 早在2月,团队就已发表ViT-22B论文,这次则说明模型扩展方法,也就是结合了如PaLM模型采用的扩展方法,同时运用QK正规化来改善训练稳定度,以及异步平行线性操作来改善训练效率。
也由于ViT-22B有新架构和更有效率的分片配方,所以能在硬件利用率高的Cloud TPU训练。 此外,ViT-22B也因为使用冻结表示(Frozen representation)或全微调,因而在许多计算机视觉任务上都达到SOTA等级。 特别的是,ViT-22B还能整合到扩展版的大型语言模型PaLM-e中,成功执行计算机视觉和自然语言任务,大幅提高机器人任务能力。 (详全文)
OpenAI GPT-4 安全性
等了6个月才发表GPT-4,OpenAI揭露AI安全性作法
尽管生成式AI带来各种可能,也隐含不少安全风险。 OpenAI近日公开AI安全性做法,他们指出,在发表任何新系统前,团队都会进行一系列严谨的测试,并请外部专家提供回馈,藉由这种人工回馈强化学习技术来优化模型表现,同时打造监控系统,来观测模型使用状况。
OpenAI透露,正因此,他们训练完GPT-4后,额外花了6个多月来评估模型,确保模型的安全性和一致性,并有强大的监控系统,来防范滥用情况,比如用户试图上传儿童性虐相关素材时,该系统会阻止该行为并通报美国受虐儿童中心。 此外,OpenAI也与非营利组织Khan Academy合作,共同开发符合安全规范的AI助手,来作为学生的虚拟老师,也是老师的课堂助手。 OpenAI同时也正开发输出设置功能,要让开发者用来调整模型输出,能更严格控管输出内容。
同时,OpenAI也主张从实际应用来改善AI安全性。 因为,仅在实验室中评估,无法预测人们所有的运用方式。 于是,OpenAI通过API提供模型技术,让开发者将模型嵌入自己的应用程序,这种方法,让OpenAI可掌握滥用行为并有所作为,也能从现实经验中来制定更细致的政策,来预防滥用风险。 虽然现在只有ChatGPT Plus的订阅用户可使用GPT-4,OpenAI表示,他们希望以后能让更多民众使用。 (详全文)
Meta 图像分割 训练数据集
Meta开源图像分割AI模型和训练数据集
Meta最近开源图像分割AI模型和训练数据集,也就是Segment Anything Model(SAM)和Segment Anything 1-Billion(SA-1B)。 图像分割(Image segmentation)是计算机视觉的重要技术之一,它能识别特定对象的像素,并将这些像素屏蔽起来,就像是替特定对象着色一样。 图像分割可用于多种领域,如相片编辑,但要建立准确的图像分割模型,得要有大量标注的数据,以及模型基础架构。
于是,Meta发起Segment Anything项目,要打造图像分割底层模型,来降低建模、打造基础架构和数据标注的门槛。 他们训练的SAM模型经多元数据和不同任务训练,可像NLP模型一样按照提示执行,而且SAM可为图像和视频中任何物件产生屏蔽,包含训练时未遇过的对象和图像类型,涵盖多种应用情境,甚至是水底相片或细胞显微影像等新型应用领域。 Meta指出,SAM还能作为大型AI系统的一部分,或整合提示工程来发展多模态应用,如理解网页影像和文字内容,或用于AR/VR系统中,来根据用户视线选择对象,再将这个物件升级为3D对象。 (详全文)
VS Code 代码 Copilot Chat
VS Code 1.77新预览功能,开发者在程式码行内就能与AI对话
微软最近推出新版开发环境VS Code 1.77,新版本加强了GitHub链接,还提供TypeScript/JavaScript的switch陈述式自动完成功能,开发者也能使用最新的Copilot Chat整合功能,在编辑器内直接向AI提问、得到代码建议。
进一步来说,VS Code 1.77与Copilot Chat更深度整合,Copilot会在开发者处理代码时,直接在程式码行内显示建议,开发者也可随时在程式码编辑器中向Copilot提问,并要求Copilot寻找代码内的臭虫或解释代码的意义,甚至是建立测试。 Copilot的对话框现在会出现代码的下方,供用户输入指令。 开发者要使用这项深度整合功能,除了需要获得Copilot Chat访问权限外,还要安装GitHub Copilot Nightly版本扩充套件,以及Insiders版本VS Code。 (详全文)
Databricks 制造业 数据湖仓
Databricks推出制造业数据湖仓,加速数据分析和AI开发
Databricks近日推出制造业数据湖仓平台(Lakehouse for Manufacturing),在自家原有的核心数据湖仓平台上,开发出适合制造业的数据分析解决方案和预建加速器,来支持数字双生、物料预测、设备效率分析等应用。
Databricks数据湖仓是一种新型数据架构,整合了数据湖和数据仓储,可同时处理结构化和非结构化数据,且支持实时的数据处理与分析。 此前,Databricks就已针对医疗业和金融业等产业推出专用数据湖仓解决方案,现在进一步发展出制造业专用平台,单一平台就能处理制造业因庞大数据量而产生的储存和仓储链接问题,并统合结构化与非结构化数据分析作业,改善过去分析碎片化问题。 此外,用户还还能采用,支持各种工业数据应用的内置解决方案加速器,来加速数字双生、物料预测、设备效率分析、计算机视觉和预测性维护等应用的开发。 (详全文)
Meta 生成式AI 广告
Meta预计下半年用AI生成广告
Meta技术长安德鲁. 博斯沃思(Andrew Bosworth)日前透露,Meta要在广告业务中,大量使用AI来替企业客户生成广告,预计今年下半年开始。 博斯沃思接受日经亚洲采访时,说明Meta将以AI来改善核心业务,旗下产品Facebook、WhatsApp和Instagram会先开发由AI生成的广告给受众。
他指出,Meta几个月前刚成立生成式AI团队,是他与执行长扎克伯格和产品长Chris Cox投资最多时间和精力的项目。 而该团队的目标,就是要用AI来优化文字信息(应用于WhatsApp和Messenger)与图像生成(如Instagram滤镜和广告),通过AI生成广告也是目标之一,甚至未来,Meta希望通过大型语言模型来建立3D模型,进而推动虚拟世界和元宇宙业务发展。 (详全文)
图片来源/CMU、UC Berkeley、Google、Meta、微软