
OpenAI采用了一种称为过程监督(Process Supervision)的训练方法,与单纯奖励最终答案正确性的结果监督(Outcome Supervision)不同,过程监督奖励每个正确步骤的推理,使得模型能够遵循人类认可的关联思考(Chain-of-Thought),产生更可靠的结果。

虽然近期大型语言模型的推理能力大幅度提高,但OpenAI提到,即便是最先进的模型,仍会产生逻辑错误,这种错误称为幻觉(Hallucination),而解决幻觉则是建置通用人工智能的关键。
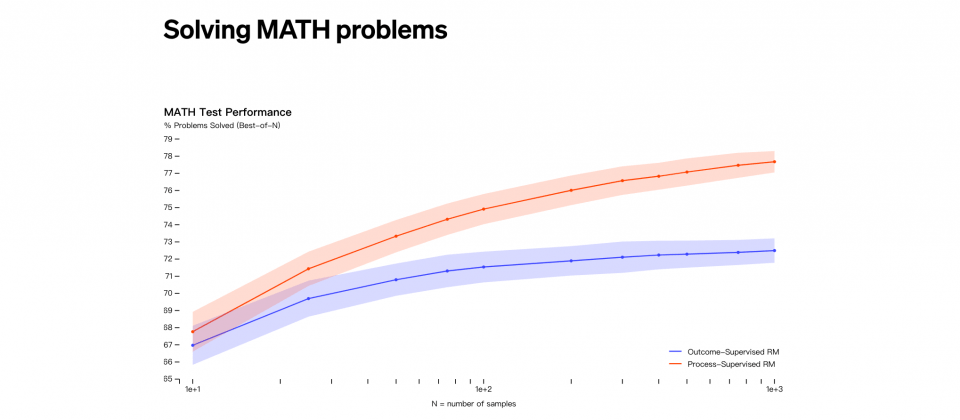
结果监督和过程监督都能够奖励模型侦测幻觉,结果监督是由最终结果提供反馈,而过程监督则是会在关联思考的每一个步骤都提供反馈,根据OpenAI在MATH测试集上的试验,过程监督能够明显取得较好的结果。
过程监督的优点是奖励模型关联思考的一致性,过程中每个步骤都会受到精确的监督,而且过程监督因为被鼓励遵循人类准许的过程,因此还能产生可解释的推理。 相比之下,结果监督可能会奖励不一致的过程,而且也更难以审查。
研究人员利用MATH测试集评估过程监督和结果监督,过程监督的效能表现较结果监督佳,而且当问题变得复杂,效能差距也会增加,整体来说,过程监督奖励模型更加可靠。
在人工智能的领域中,让人工智能系统的行为,与人类价值观一致的方法,被称为对齐方法(Alignment Method),但通常更安全,且与人类价值观更一致的方法,代表着可能导致效能下降,而这种副作用称为对齐成本(Alignment Tax),研究人员提到,对齐成本会对模型部署产生压力,因此会直接影响对齐方法的采用。
幸运的是,根据实验结果,在数学领域,过程监督的对齐成本为负,而这可能促使过程监督被积极采用。 虽然目前研究人员还不确定这项研究可以多大程度扩展至数学领域之外,但是研究过程监督对于其他领域的工作相当重要,当这些研究结果具有普遍性,则过程监督便成为更高效且一致的方法。