


NVIDIA推出支持Stable Diffusion WebUI的TensorRT运算框架优化插件,能够明显提升图像生成的速度。
插件安装与模型转换
为了要获得加速的效果,用户需要完成TensorRT运算框架优化插件的安装,以及Checkpoint或LoRA等模型转换等前置工作,才能在算图时发挥加速的效果。
根据NVIDIA的说明,目前插件正式版支持Stable Diffusion 1.5 / 2.1,且可支持套用LoRA小模型与Hires. Fix功能,如果想要使用SDXL版本的模型,则需切换至Stable Diffusion WebUI的Dev分支。 由于NVIDIA说明未来会正式将SDXL纳入支持,所以目前我们就暂时不讨论抢先试用开发中版本的部分。
不过需要注意的是,目前TensorRT插件仅可套用1组LoRA,若套用多组则仅于sd_unet选单指定的单一LoRA有效,造成比较大的使用限制,未来若能支持多组LoRA则可大幅提升方便性。
插件安装与模型转换请参考下列图文说明。 其中建议读者在转换过程中展开自定选项,并根据需求修改参数。 如果需要使用Hires. Fix功能,则需将分辨率参数的范围设置大于目标生成图像的分辨率。
进阶设置说明
Min / Optimal / Max batch-size:最小 / 最佳 / 最大批次算图数量。 若显示内存为10GB以下,建议设置为1。 若为16GB以上,则可尝试1~4等数值。
Min / Optimal / Max height:最小 / 最佳 / 最大分辨率高度。 建议设置512~2048,以利使用Hires. Fix功能。
Min / Optimal / Max width:最小 / 最佳 / 最大分辨率宽度。 建议设置512~2048。
Min / Optimal / Max prompt token count:最小 / 最佳 / 最大提示词数量。 建议设置75~300。
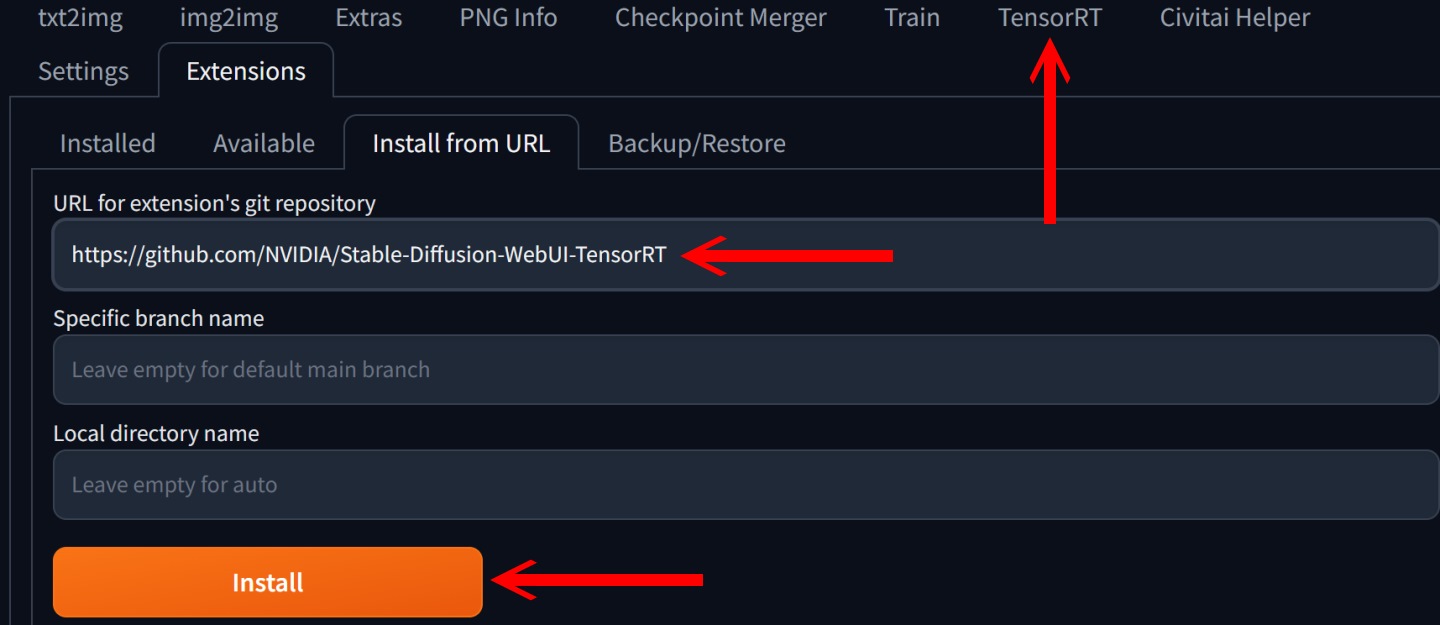
▲ 插件的安装相当简单。 开启Stable Diffusion WebUI界面后,先至Extensions页面并选择Install from URL,在URL字段输入「https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT」,并按下Install即可。
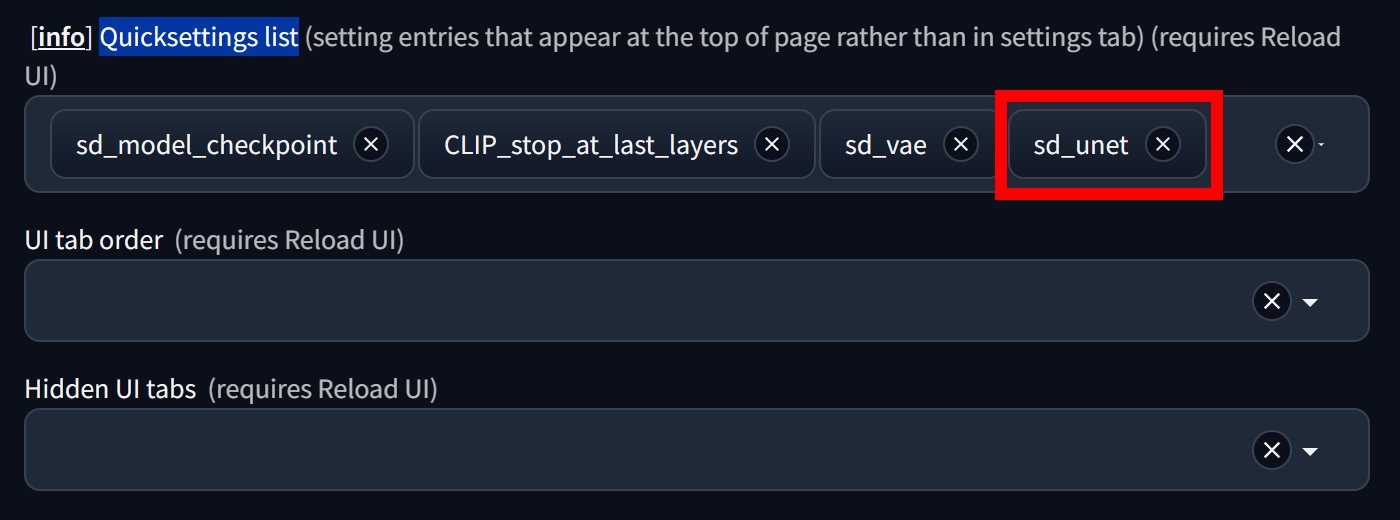
▲ 接下来到Setting页面,找到Quicksettings list项目,手动输入「sd_unet」。 完成这2步后,完全关闭Stable Diffusion WebUI再重新开启。
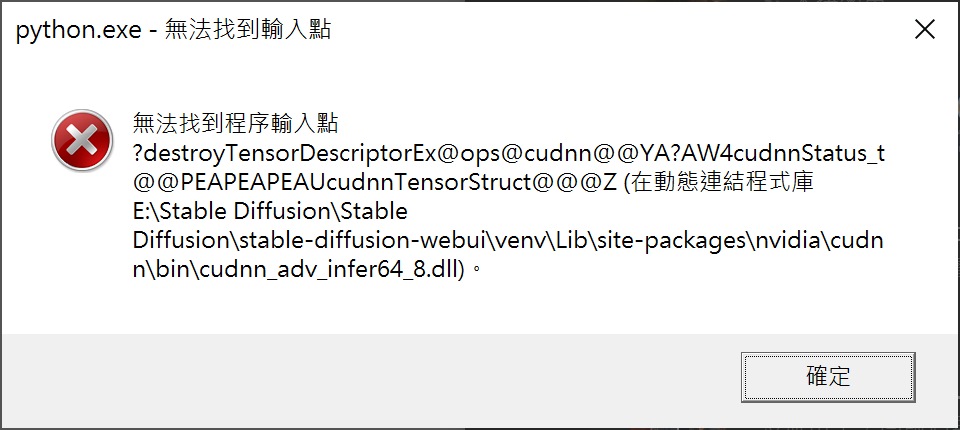
▲ 目前笔者在开启程序时会跳出4个缺少文件的错误消息,但是检查后文件都存在。 由于不影响后续操作,故略过这些错误消息。
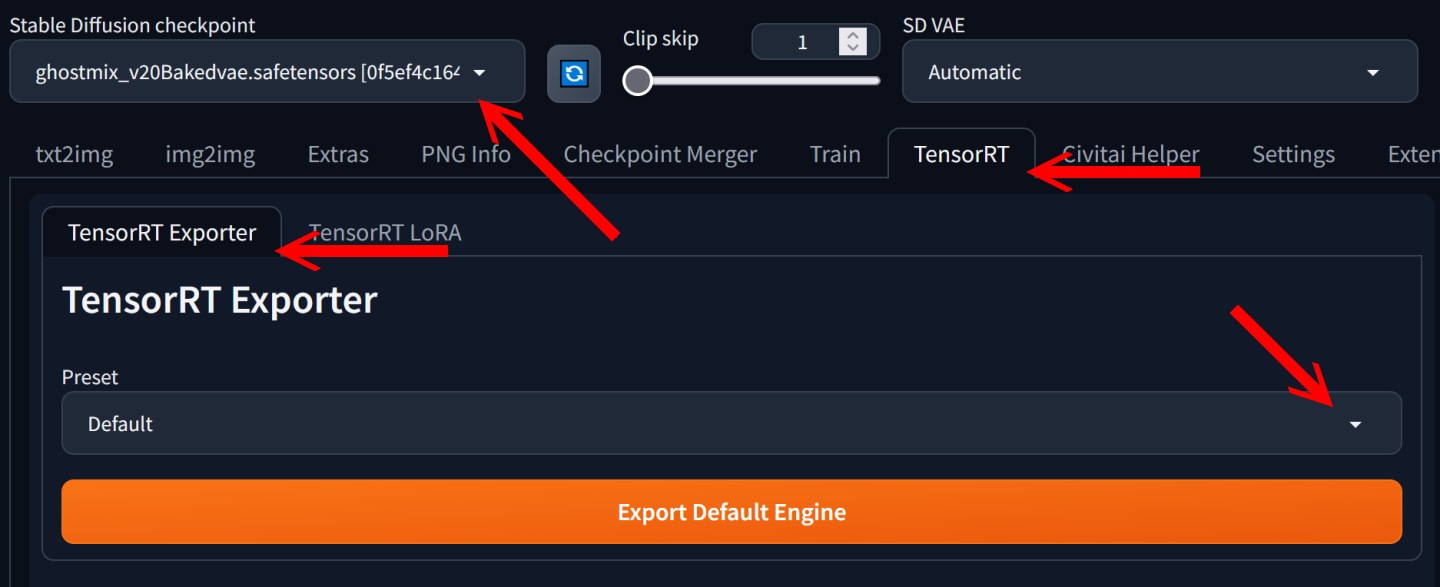
▲ 重新启动Stable Diffusion WebUI之后,进入TensorRT标签下的TensorRT Exporter标签,在左上角然后选择Stable Diffusion Checkpoint下拉式菜单选择要转换的模型,建议在Preset下拉式菜单选择「768×768 – 1024×1024 | Batch Size 1-4 (Dynamic)」,并点击Advanced Settings展开高级设置。
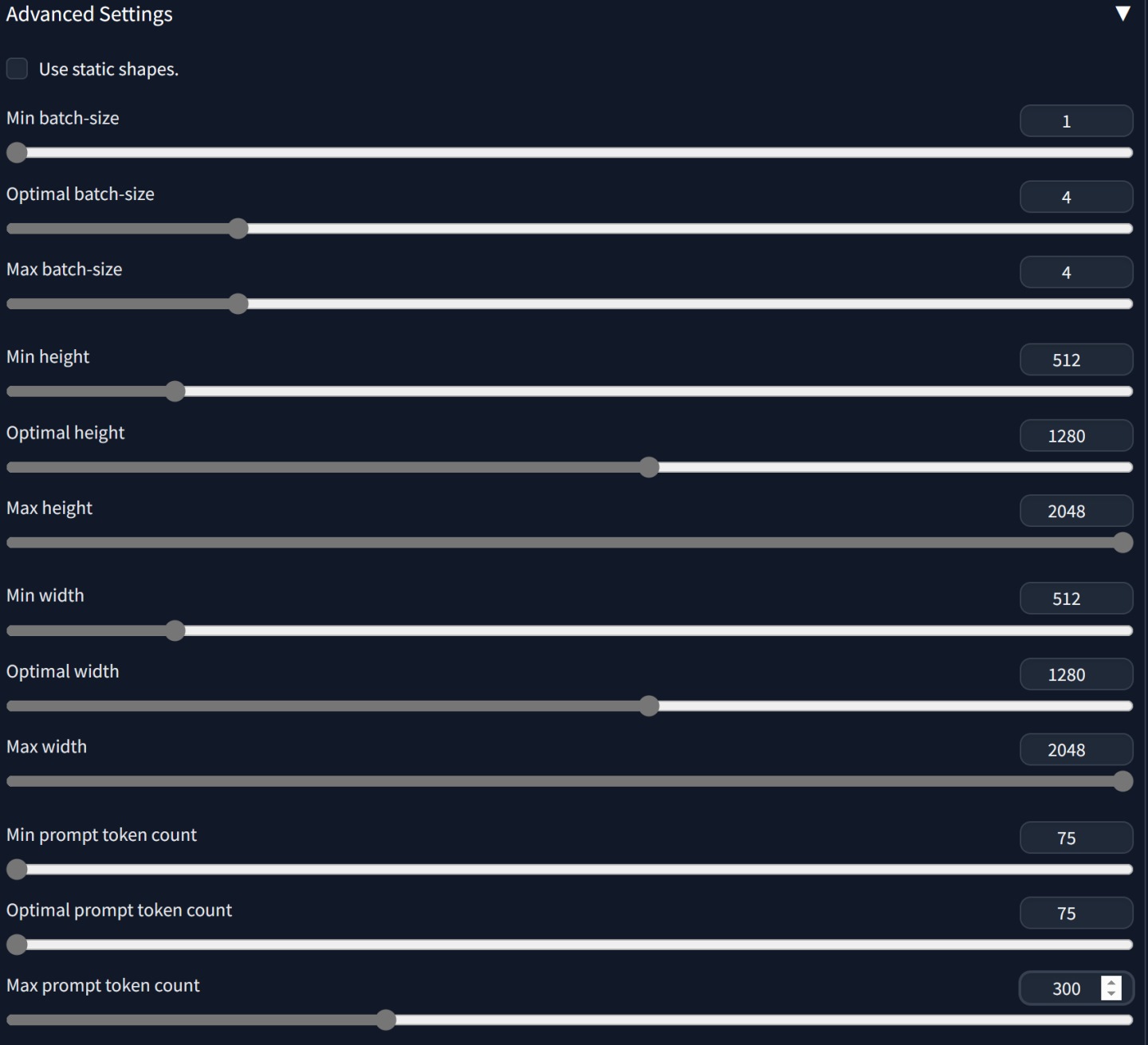
▲ 进阶设置的参考画面,可依需求调整设置。
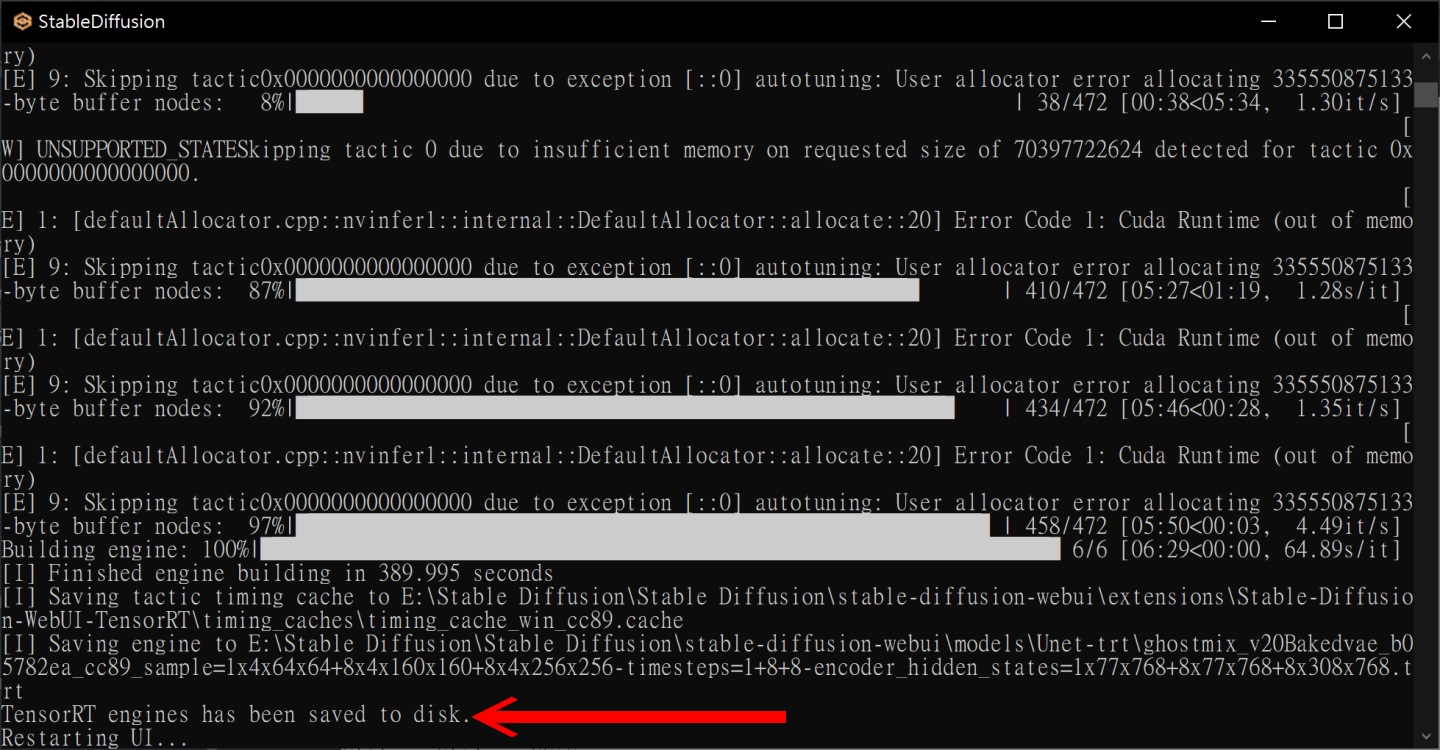
▲ 设置完成后点击下方Export Engine按钮,并等待转换工作完成。
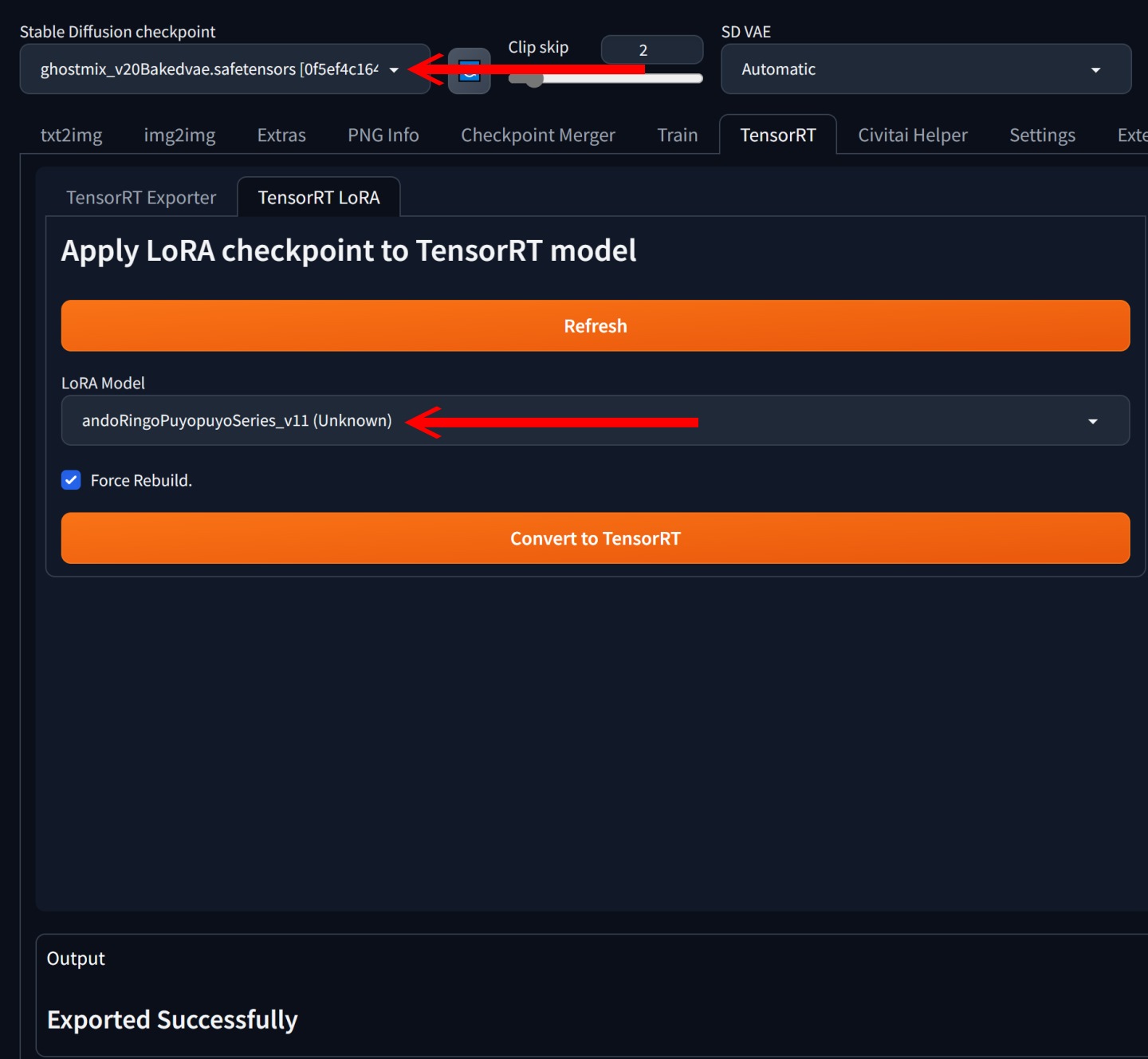
▲ LoRA的转换工作比较简单,进入TensorRT标签下的TensorRT LoRA标签,一样需要在Stable Diffusion Checkpoint选择要转换的模型,并在LoRA Model下拉式菜单选择搭配的LoRA,之后点击Convert to TensorRT按钮。
可正确启用1组LoRA
完成前置作业后,用户只需在Unet下拉式菜单中选取指定的Checkpoint或LoRA模型,其余设置皆依照一般图像生成即可。
需要注意的是,无论是否使用Hires. Fix功能,在放大前、后的分辨率都必需设置为64的整数倍(例如768 x 512,或1920 x 1280),而且需要小于转换模型时的设置值。
要使用LoRA的话,则需在Unet下拉式菜单指定的LoRA,且仅有该组LoRA会在图像生成时产生作用。 若在提示词中写入其他LoRA,虽然照样能够完成图像生成并输出,但该部分提示词就不会产生作用。
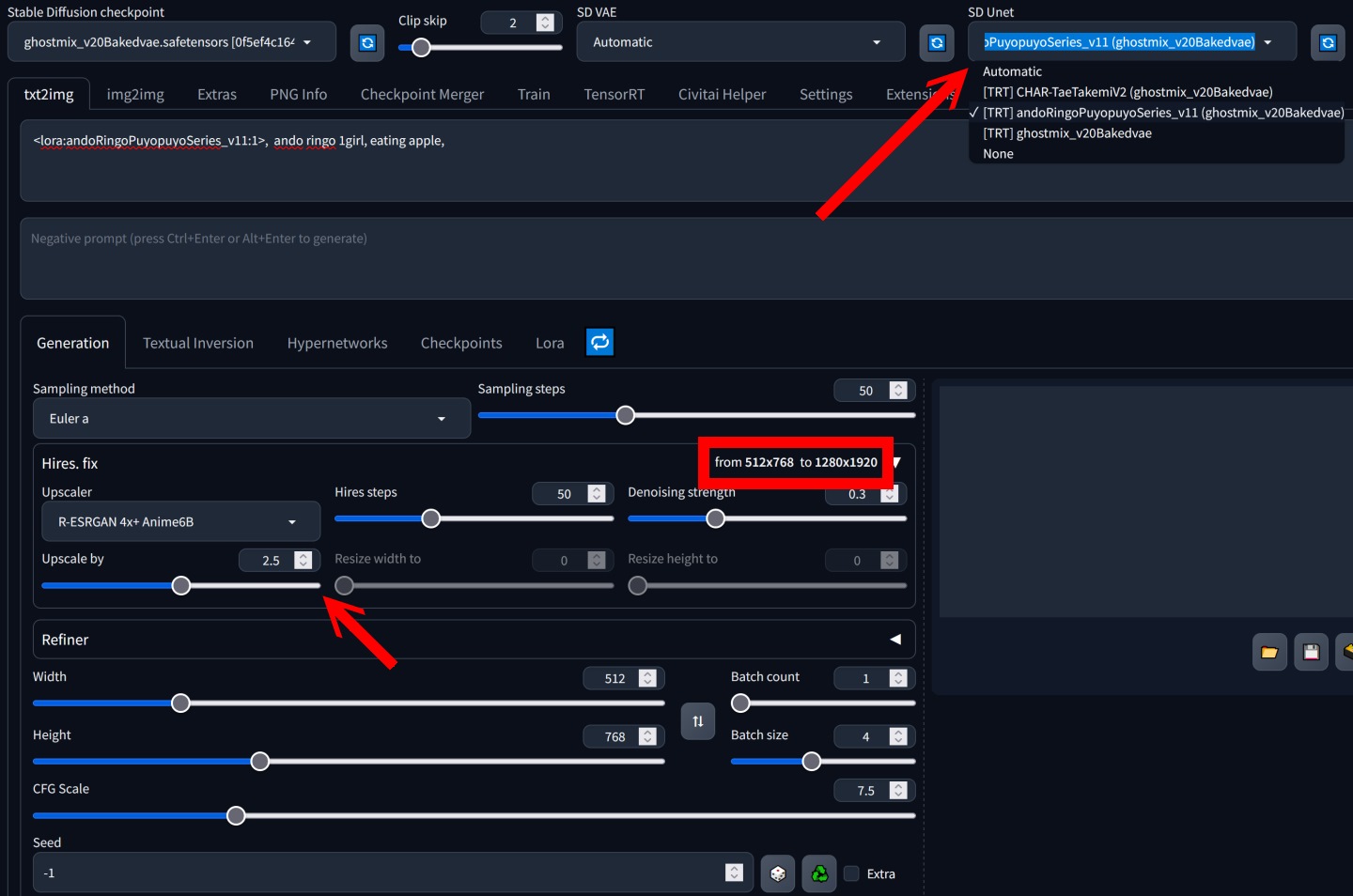
▲ 如果想要启用TensorRT,需要在SD Unet下拉式菜单中选取指定的Checkpoint或LoRA模型,需要注意只能选择1组LoRA,其他于提示词中加入的LoRA不会生效。 另一方面,如果要使用Hires. Fix功能的话,放大后的分辨率不能超过转换模型时的设置。
![若一切设置正常,在算图时就可看到Activating unst : [TRT]的消息。](https://www.mobbang.com/wp-content/uploads/2024/12/2024120308450653.jpg)
▲ 若一切设置正常,在算图时就可看到Activating unst : [TRT]的信息。
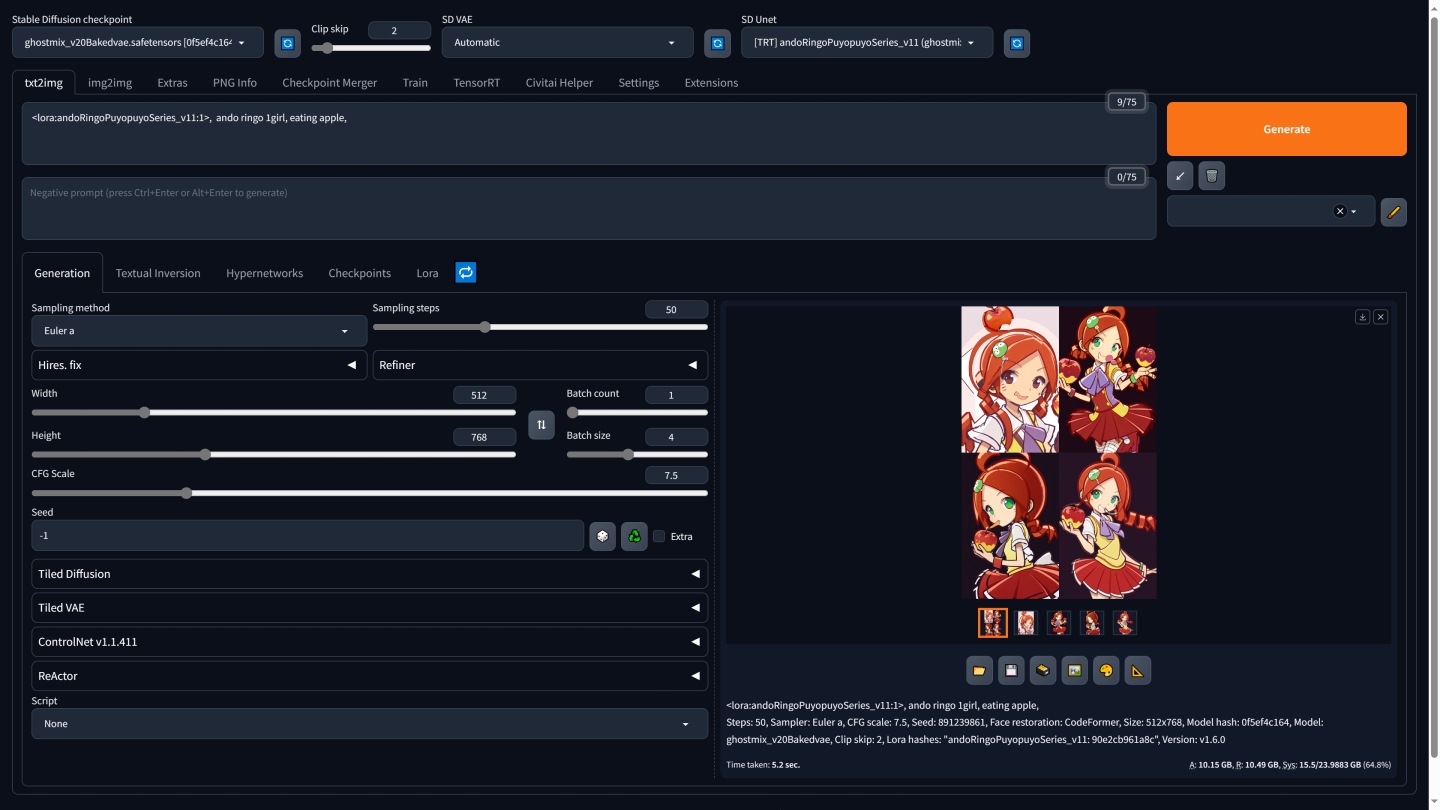
▲ 经测试验证,正式版TensorRT插件能够正确启用LoRA小模型与Hires. Fix功能。
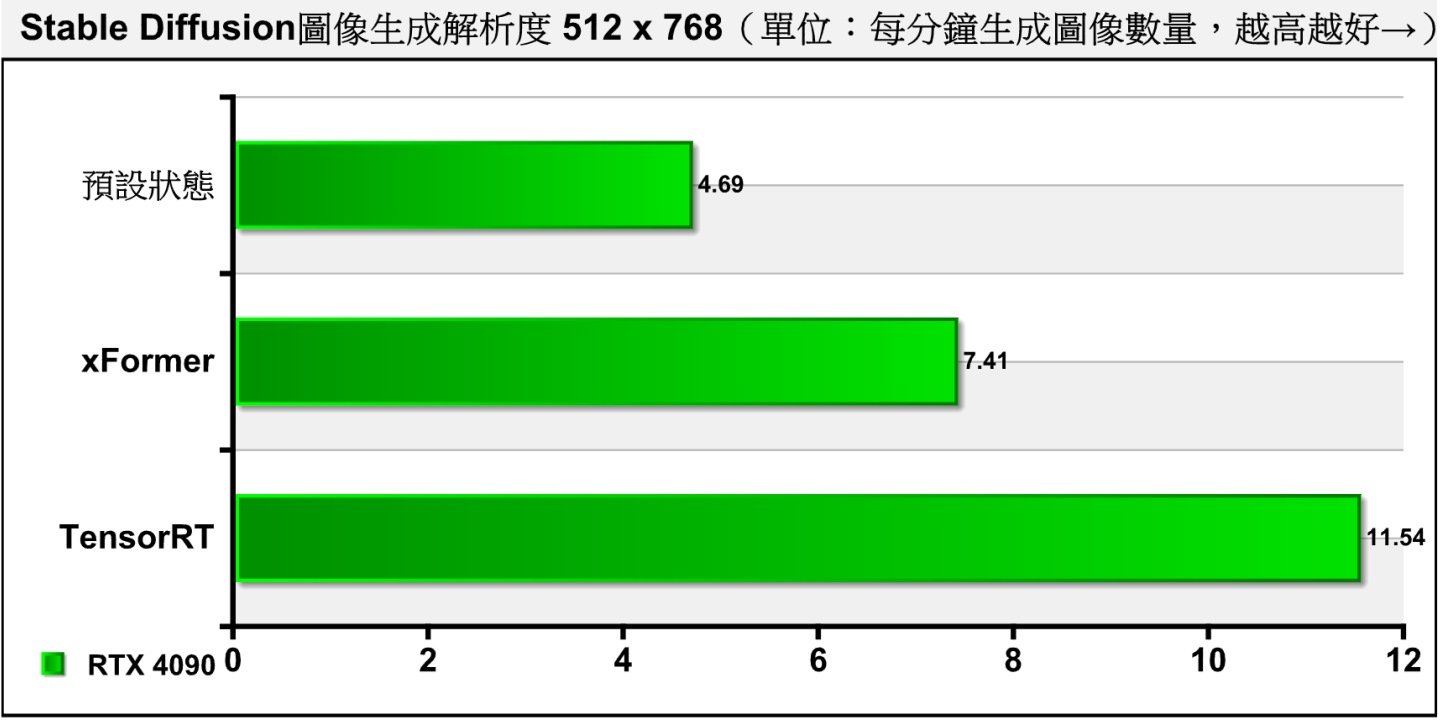
▲ 在实际测试中,可以看到原有的xFormer可以提升约58%算图速度,而TensorRT可以提升146%速度,效果更显著。
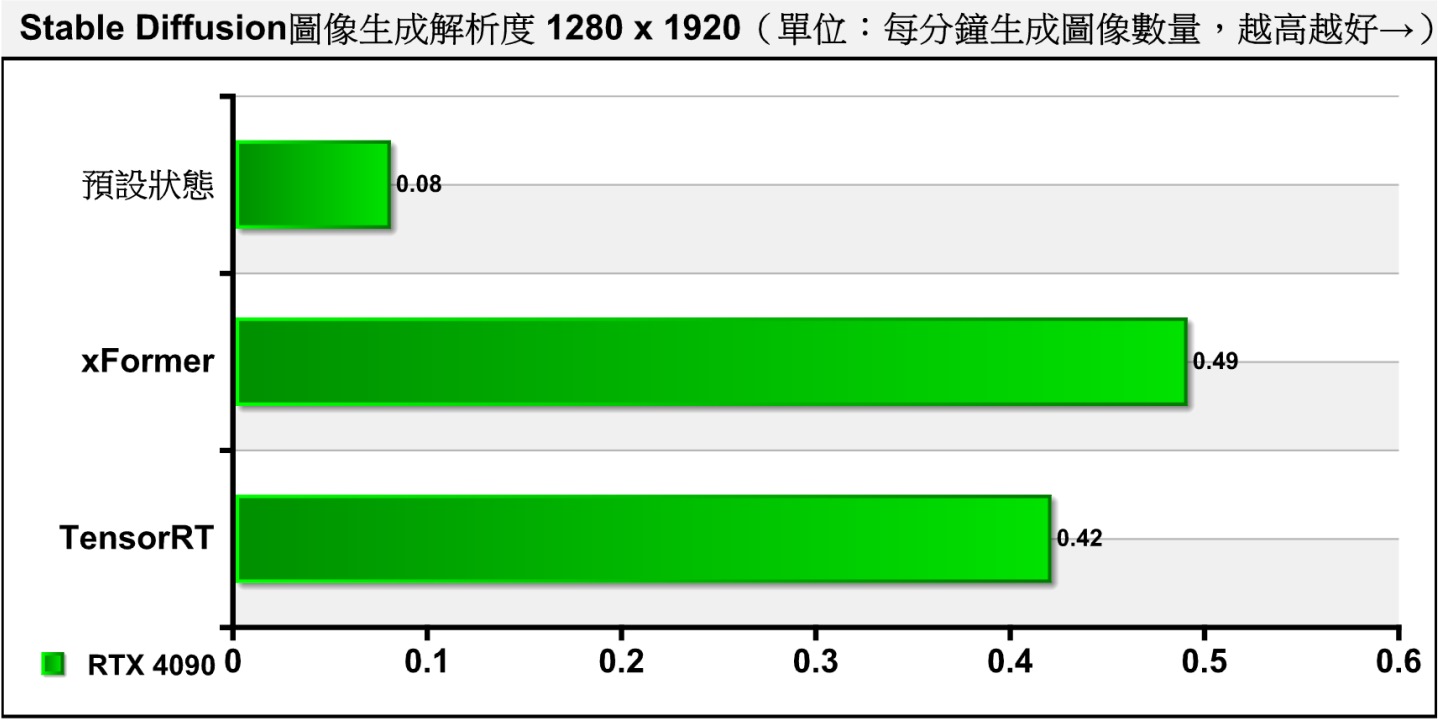
▲ 不过在使用Hires. Fix功能时,xFormer与TensorRT的效能表现却差不多。
从测试结果可以看到,TensorRT能在不使用Hires. Fix功能时带来明显的加速效果,而在使用时则没什么帮助。
与之前的开发中版本相比,这次使用的版本已经可以正确发挥LoRA小模型的效果已经能发挥更大的实用价值,若能套过多组LoRA并提升Hires. Fix效能,则可带来更大的便利。